Claude Opus 4.7:AI 安全的新范式

Anthropic 在 4 月 16 日发布了 Claude Opus 4.7,这不仅是一次性能升级,更是 AI 安全领域的一次重要实验。
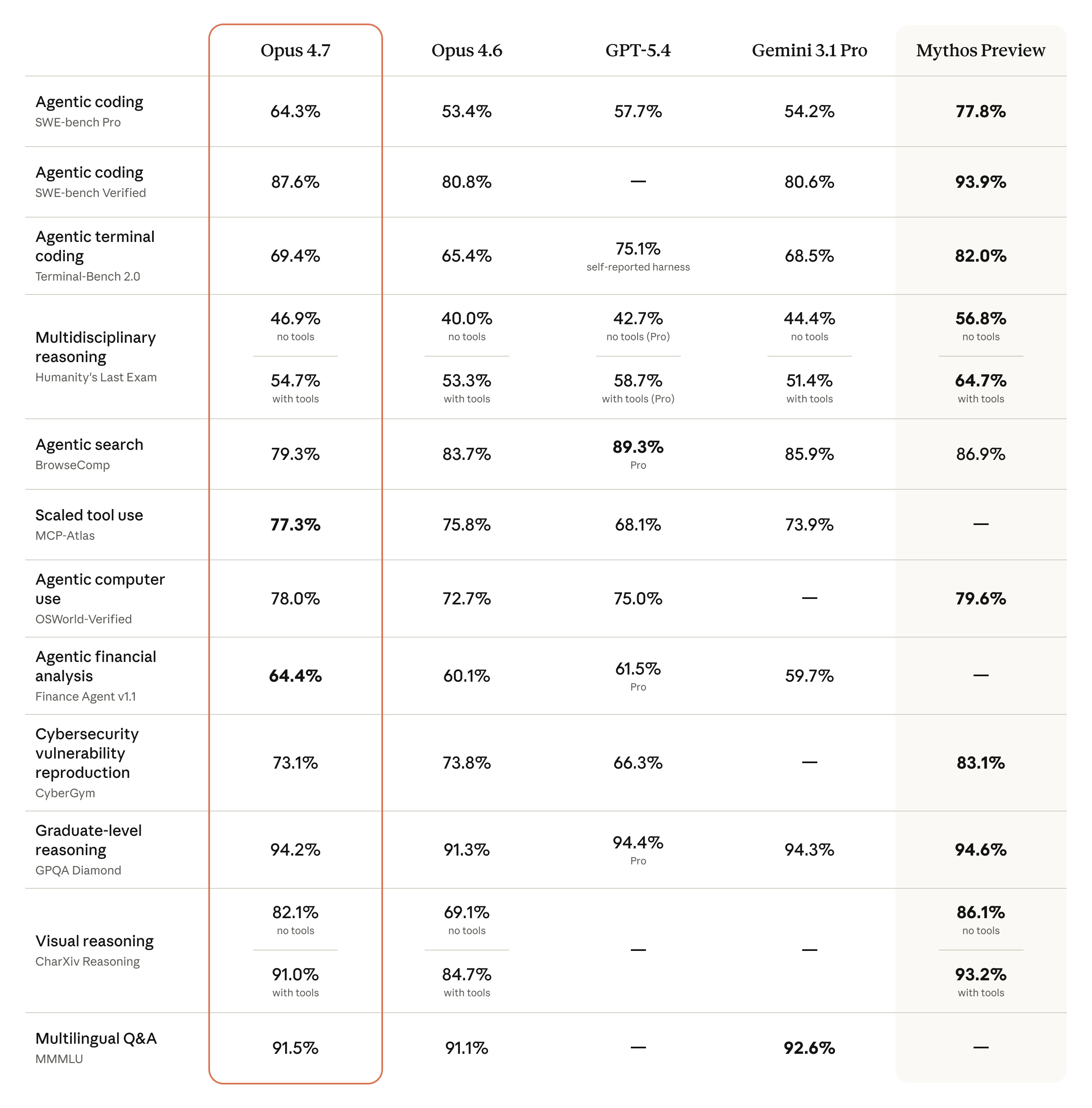
性能提升:从监督到放手
Opus 4.7 在软件工程任务上的表现让人印象深刻。早期测试者反馈,那些以前需要密切监督的复杂编码任务,现在可以放心交给 Opus 4.7 独立完成。模型在处理长时间运行的任务时表现出更强的严谨性和一致性,能够精确遵循指令,甚至会在报告结果前主动验证自己的输出。
视觉能力也有显著提升——更高的图像分辨率处理能力,在生成界面、幻灯片和文档时展现出更好的品味和创造力。虽然整体能力不如 Anthropic 最强大的 Claude Mythos Preview,但在多项基准测试中超越了 Opus 4.6。
 Opus 4.7 的网络安全防护系统会自动检测并阻止高风险的网络安全请求
Opus 4.7 的网络安全防护系统会自动检测并阻止高风险的网络安全请求
安全优先:差异化能力削减
真正值得关注的是 Anthropic 的安全策略。在上周宣布的 Project Glasswing 中,Anthropic 明确指出 AI 模型在网络安全领域的双刃剑特性。他们决定限制 Claude Mythos Preview 的发布范围,并在能力较弱的模型上率先测试新的网络安全防护措施。
Opus 4.7 就是第一个这样的模型。在训练过程中,Anthropic 实验性地差异化削减了其网络安全能力——这是一个大胆的尝试。模型配备了自动检测和阻止高风险网络安全请求的防护机制。这些防护措施在真实世界部署中的表现,将为未来 Mythos 级别模型的广泛发布提供经验。
对于需要将 Opus 4.7 用于合法网络安全目的(如漏洞研究、渗透测试、红队演练)的安全专业人员,Anthropic 推出了新的 Cyber Verification Program。
行业反馈:速度与精度的平衡
早期测试者的反馈很有说服力:
-
Plaid 的技术副总裁 Clarence Huang 提到,Opus 4.7 能在规划阶段捕获自己的逻辑错误,并加速执行——这种速度与精度的结合对金融科技平台至关重要。
-
Replit 的 CTO Igor Ostrovsky 认为 Opus 4.7 在处理异步工作流(自动化、CI/CD、长时间运行任务)方面表现出色,并且”对问题思考更深入,带来更有主见的观点,而不是简单地同意用户”。
-
Hex 的 CTO Caitlin Colgrove 强调,Opus 4.7 在数据缺失时会正确报告,而不是提供看似合理但实际错误的回退方案——这是数据分析场景中的关键能力。
定价与可用性
Opus 4.7 现已在所有 Claude 产品、API、Amazon Bedrock、Google Cloud Vertex AI 和 Microsoft Foundry 上线。定价与 Opus 4.6 保持一致:输入 token 每百万 5 美元,输出 token 每百万 25 美元。
思考:AI 安全的工程化路径
Anthropic 的做法展示了一种务实的 AI 安全路径:不是等到”完美的安全方案”才发布模型,而是在能力较弱的模型上迭代测试防护措施,从真实世界的部署中学习。差异化能力削减(differentially reducing capabilities)这个概念尤其有趣——它意味着我们可以在训练阶段就针对特定风险领域进行干预,而不仅仅依赖后期的内容过滤。
这种”先测试、再推广”的策略,可能会成为未来强大 AI 模型发布的标准流程。
如果你在多个 AI 模型之间频繁切换,推荐试试 OfoxAI(ofox.ai)— 一个账号搞定 Claude、GPT、Gemini 等主流模型。