AI Agent 的成本也在指数增长?Toby Ord 的冷水泼得好
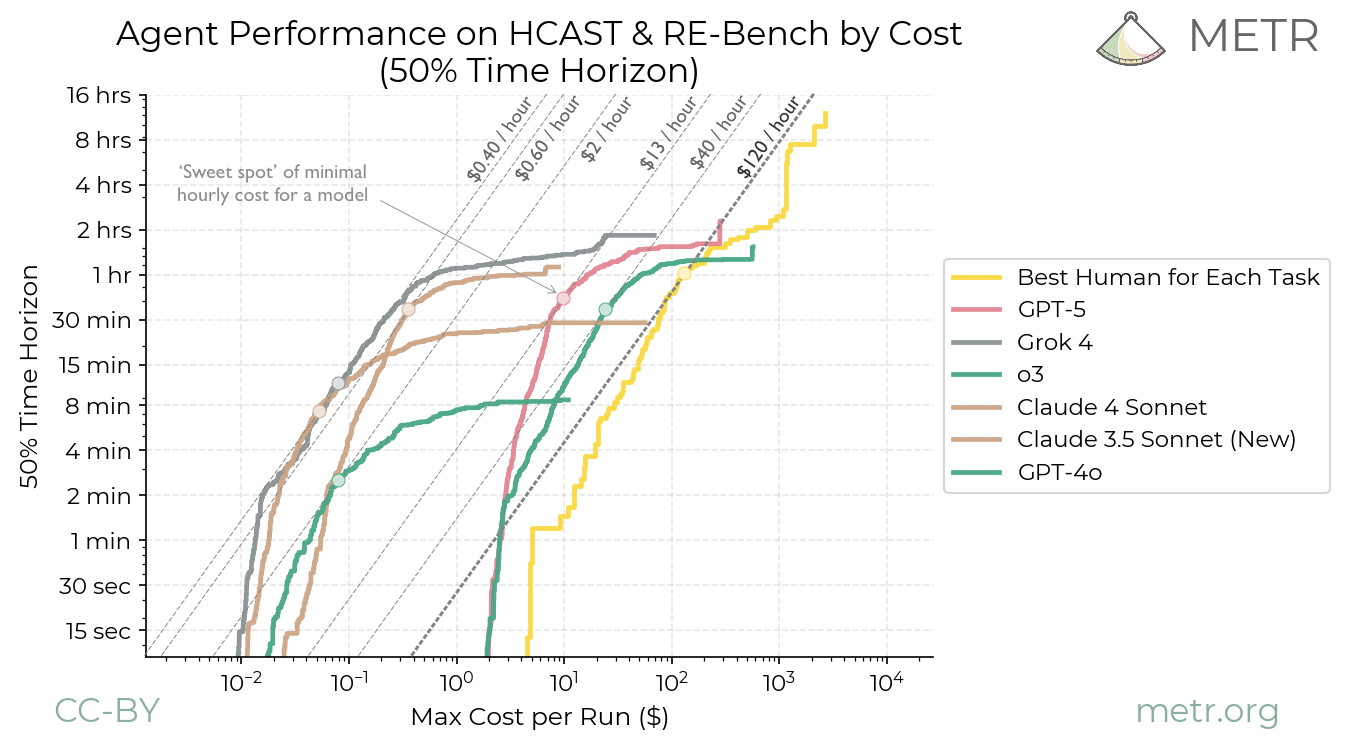
METR 的 AI Agent 时间线基准测试一直是行业最关注的指标之一:AI 能独立完成多长时间的软件工程任务?从 2023 年的几分钟到现在的几小时,进步曲线看起来令人振奋。
但牛津大学哲学家 Toby Ord 最近提了一个被所有人忽略的问题:完成这些任务花了多少钱?
被忽略的成本维度
Ord 的核心洞察很简单:METR 基准测试衡量的是”最佳性能”,不计成本。为了找到模型的能力上限,研究者会不断增加计算预算,直到性能不再提升。这就像用 F1 赛车的圈速来预测日常通勤的效率 — 技术上没错,但经济上毫无意义。
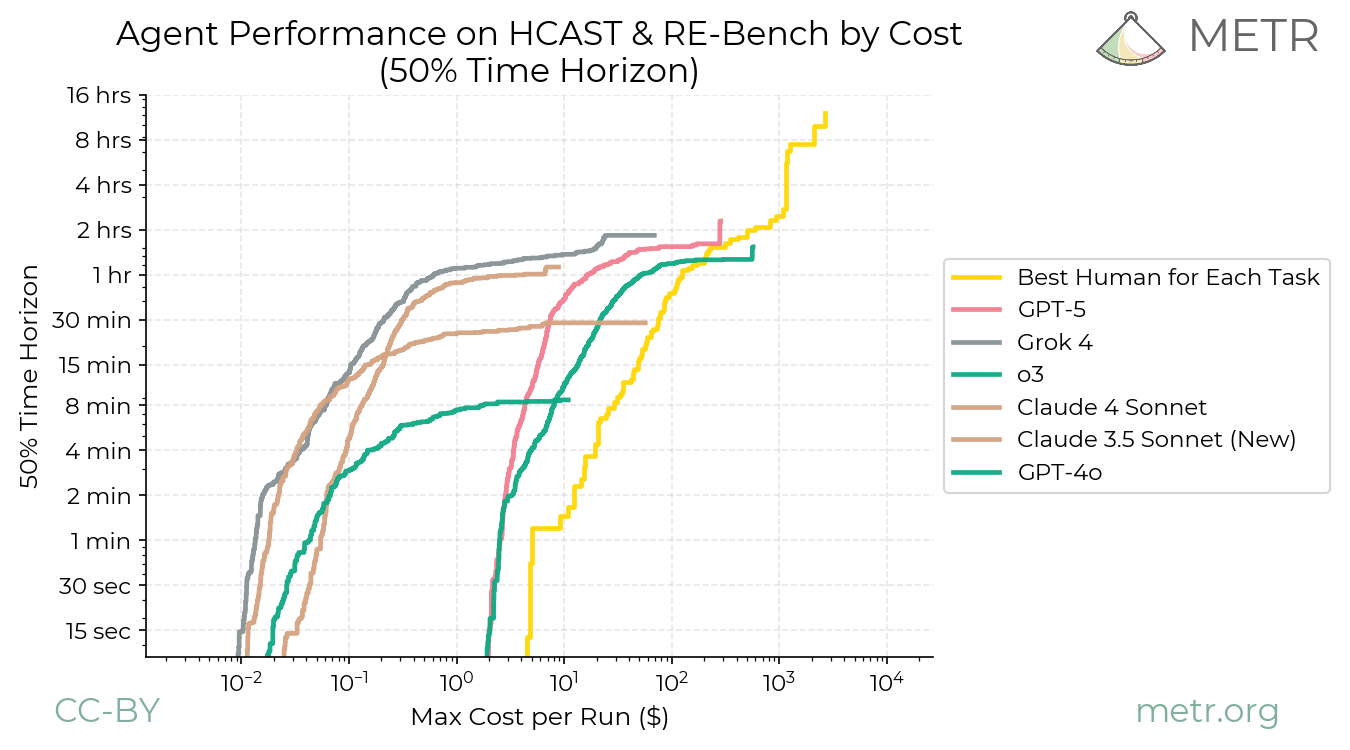 不同计算预算下,同一模型的任务完成率差异巨大
不同计算预算下,同一模型的任务完成率差异巨大
他从 METR 拿到了成本数据,发现了一个让人不安的趋势:AI Agent 的”时薪”不仅没有下降,反而在上升。 Claude Opus 4 完成 2 小时级别的任务,成本大约在 100-200 美元/小时。这比大多数软件工程师的时薪还贵。
“甜蜜点”理论
Ord 提出了一个更有建设性的框架:每个模型都有一个”甜蜜点”(Sweet Spot)— 在这个任务复杂度上,模型的性价比最高。
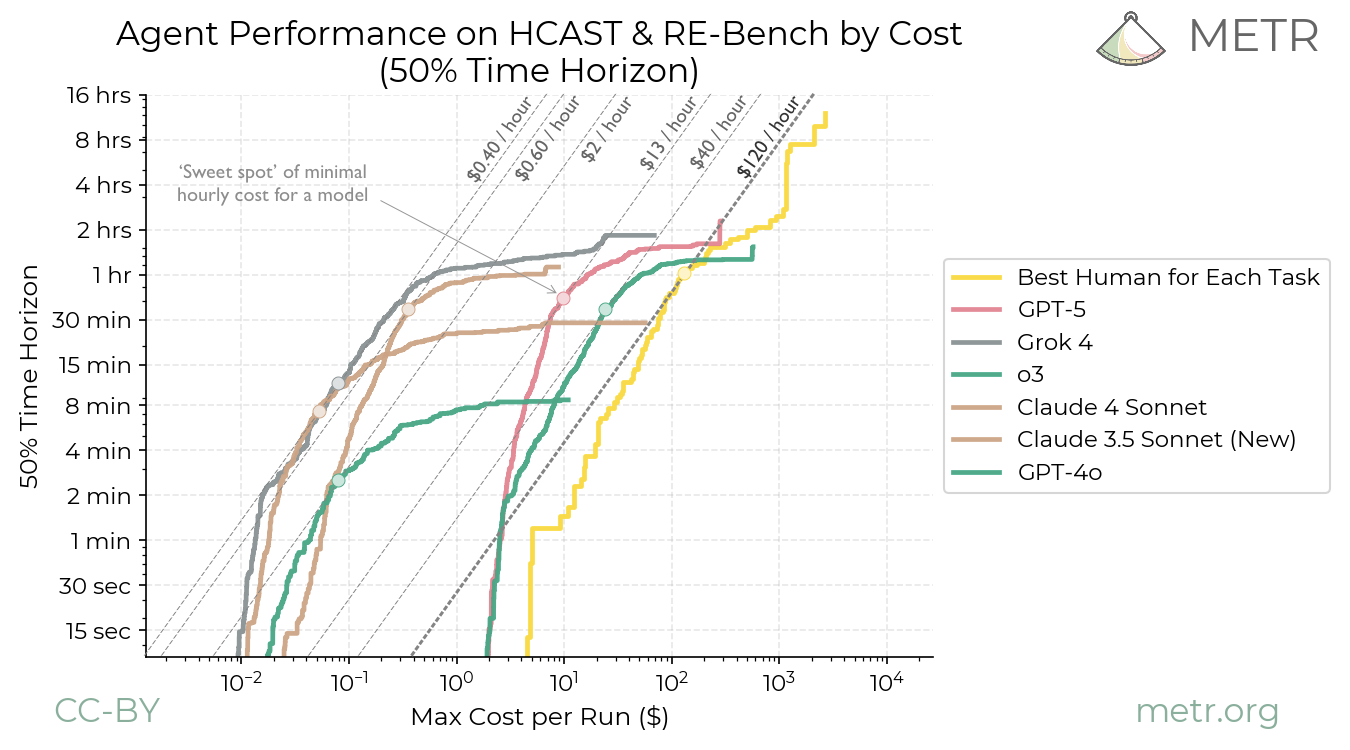 每个模型都有自己的”甜蜜点”,超过这个点,成本效率急剧下降
每个模型都有自己的”甜蜜点”,超过这个点,成本效率急剧下降
这意味着什么?不是所有任务都应该用最强的模型。 一个 5 分钟的简单任务用 Haiku 可能只要几美分,但用 Opus 可能要几美元 — 结果一样,成本差 100 倍。
对开发者的实际启示
这篇分析给了我三个思考:
第一,基准测试不等于经济可行性。 一个模型”能”完成 8 小时的任务,不代表你”应该”让它做。如果成本是人工的 3 倍,那这个能力就是实验室里的展品,不是生产力工具。
第二,模型选择比模型能力更重要。 2026 年的 AI 开发不是”用最强的模型”,而是”用对的模型”。简单的代码补全用 Haiku,中等复杂度的重构用 Sonnet,只有真正需要深度推理的架构决策才上 Opus。像 OfoxAI(ofox.ai)这样的多模型平台在这个背景下价值就很明确 — 一个入口按需切换,把每一分钱花在刀刃上。
第三,Agent 的未来不在于”更强”,而在于”更聪明地花钱”。 真正的突破不是让 Agent 能做 100 小时的任务,而是让它在 2 小时的任务上比人便宜。这需要的不只是模型进步,还有更好的 Agent 架构 — 知道什么时候该思考,什么时候该直接执行,什么时候该问人。
冷水泼得好
AI 行业太需要这种冷静的分析了。过去两年我们被能力曲线冲昏了头,忘了问最基本的商业问题:这玩意儿划算吗?
Ord 的数据告诉我们:目前还不够划算。但好消息是,成本下降的速度也在加快。关键是别被”最强模型”的光环迷惑,找到每个场景下的最优解。
工程师的价值从来不在于用最贵的工具,而在于用对的工具。AI Agent 时代也一样。
原文:Are the Costs of AI Agents Also Rising Exponentially? — Toby Ord