OpenAI Model Spec 深度解读:AI 行为规范的工程化治理
昨天 OpenAI 发布了一篇重磅博文,详细阐述了 Model Spec 的设计哲学和演进机制。这不是又一篇 AI 安全的空洞宣言——它揭示了一个关键工程问题:当你的产品是一个会”说话”的模型,你怎么定义它该说什么、不该说什么? Model Spec 是什么 简单说,Model Spec 是 OpenAI 给模型写的”行为规范”。它定义了模型如何遵循指令、如何解决冲突、如何尊重用户自由、...
昨天 OpenAI 发布了一篇重磅博文,详细阐述了 Model Spec 的设计哲学和演进机制。这不是又一篇 AI 安全的空洞宣言——它揭示了一个关键工程问题:当你的产品是一个会”说话”的模型,你怎么定义它该说什么、不该说什么? Model Spec 是什么 简单说,Model Spec 是 OpenAI 给模型写的”行为规范”。它定义了模型如何遵循指令、如何解决冲突、如何尊重用户自由、...
Anthropic 发布了 Claude Code 的 Auto Mode —— 用 AI 分类器自动判断操作是否安全,让你不用再疯狂点「批准」。93% 的权限请求其实不需要人看,但剩下的 7% 可能删掉你的生产数据库。 问题:审批疲劳 用过 Claude Code 的开发者都知道这个痛点:每写一个文件、每执行一条命令,都要弹出权限确认。这是安全设计,但也意味着你大部分时间在当「人肉审...
ARC Prize Foundation 在 Y Combinator 总部发布了 ARC-AGI-3 —— 史上第一个交互式 AI 推理基准。人类得分 100%,前沿 AI 模型不到 1%。这不是 AI 不够聪明,而是 AI 根本不会「学习」。 从静态拼图到交互式游戏 ARC-AGI 系列由 Keras 之父 François Chollet 在 2019 年创立,一直是衡量 AI ...

The Information 今天爆了一个料:Google 把 Gemini 模型的完整访问权限给了 Apple,而且允许 Apple 做蒸馏(distillation)——也就是从大模型中提取知识,训练出能在 iPhone、iPad 上本地运行的小模型。 这不是简单的”接入 API”。Apple 能在自己的数据中心里跑完整的 Gemini,拿到推理过程和高质量输出,再用这些数据去训练专...
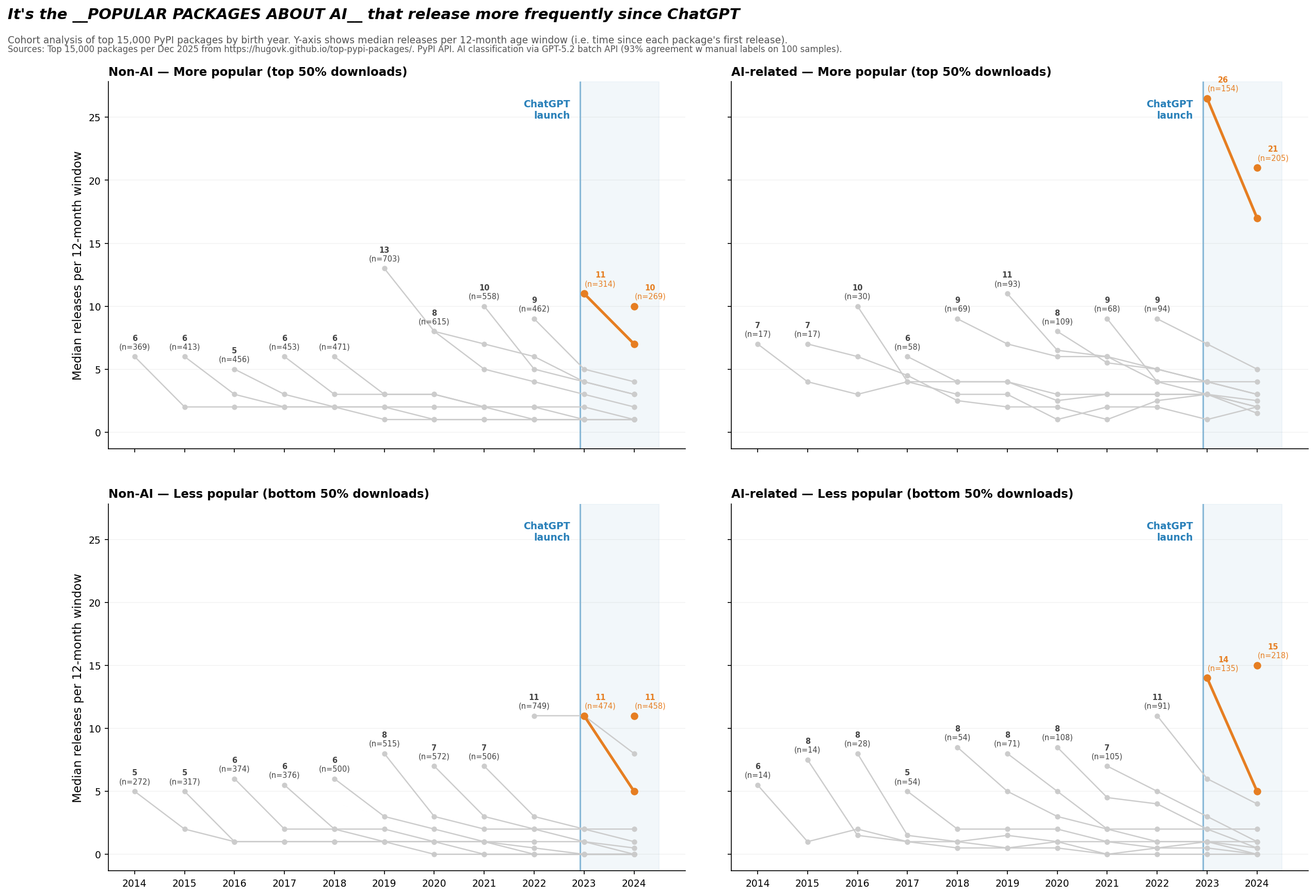
Answer.AI 最近发了一篇数据驱动的文章,标题很直白:So where are all the AI apps? 问题很简单 —— 如果 AI 编程工具真的让开发者效率提升了 2 倍、10 倍甚至 100 倍,那这些多出来的产出去哪了? PyPI 的数据不说谎 他们选了 PyPI(Python 包仓库)作为观测指标。逻辑很清晰:如果软件生产力真的爆发了,最大的公共代码仓库应该能看...

LLM 推理的瓶颈,早就不是算力了 —— 是内存带宽。 Google Research 昨天发布了 TurboQuant,一个针对 LLM Key-Value Cache 的极限压缩框架。数字很漂亮:内存占用降低 6 倍,推理速度提升最高 8 倍,精度几乎零损失。更关键的是,它是 data-oblivious 的 —— 不需要针对特定数据集校准,开箱即用。 KV Cache:长上下文推理...
项目地址: github.com/t8/hypura 配图来源: 项目 README 32GB 内存的 Mac 能跑 40GB 的模型吗? 正常情况下不行。llama.cpp 会因为内存不足直接崩溃,macOS 的 swap 机制会疯狂抖动直到 OOM killer 把进程杀掉。 但 Hypura 说可以。它是一个面向 Apple Silicon 的 LLM 推理调度器,通过理解...

Mozilla AI 团队最近开源了一个项目叫 cq(colloquy 的缩写),定位很直接:Stack Overflow for AI Agents。 这个项目的出发点很有意思,也很讽刺。 Stack Overflow 的死亡螺旋 数据是残酷的:Stack Overflow 月提问量从 2014 年巅峰的 20 万+,跌到 2025 年 12 月的 3,862 条 —— 回到了 20...

作为 OfoxAI(ofox.ai)的开发者,我每天都在和不同的 AI 模型打交道。所以当我在 Hacker News 上看到一篇 581 分的帖子标题是「Is anybody else bored of talking about AI?」的时候,第一反应不是被冒犯,而是 —— 终于有人说了。 锤子综合征 原文作者 Jake Saunders 打了个比方:这就像你去木工论坛,结果所有人...
今天 HN 上一条推文炸了:开发者 anemll 演示了 iPhone 17 Pro 直接运行一个 400B 参数的大语言模型,热度 599 分,评论区直接炸开。 一年前这事儿还被认为”不可能”。现在它发生了。 这到底是怎么做到的 关键词:MoE(Mixture of Experts)+ SSD 流式加载。 400B 参数听起来吓人,但这是一个 MoE 架构的模型 —— 并非所有参数...