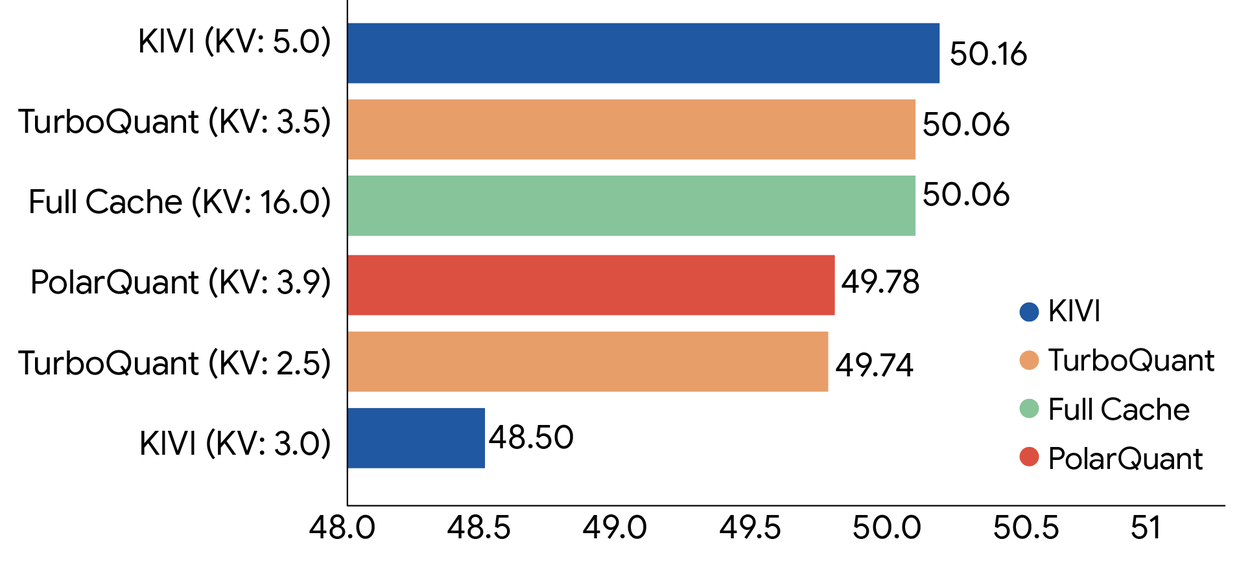
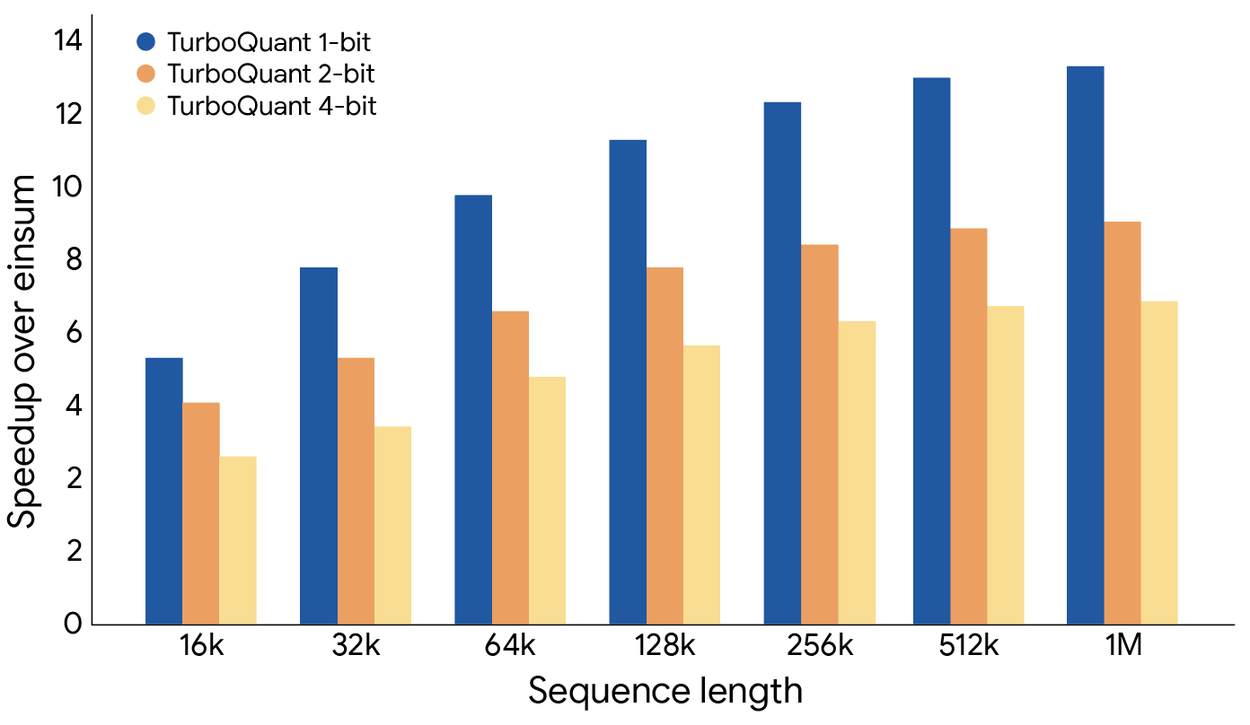
Google TurboQuant:KV Cache 压缩 6 倍,推理加速 8 倍,精度零损失

LLM 推理的瓶颈,早就不是算力了 —— 是内存带宽。
Google Research 昨天发布了 TurboQuant,一个针对 LLM Key-Value Cache 的极限压缩框架。数字很漂亮:内存占用降低 6 倍,推理速度提升最高 8 倍,精度几乎零损失。更关键的是,它是 data-oblivious 的 —— 不需要针对特定数据集校准,开箱即用。
KV Cache:长上下文推理的老大难
Transformer 做推理时,每一层都要维护 Key 和 Value 的缓存,用于注意力计算。上下文越长,KV Cache 越大。当你跑一个 8B 模型处理 100K token 的输入时,KV Cache 本身可能就吃掉几个 GB 的显存。
这不只是”能不能放下”的问题,更是 HBM(高带宽内存)和 SRAM 之间的数据搬运瓶颈。模型再快,卡在 memory wall 上就是白搭。
现有的量化方案,比如 Product Quantization(PQ),需要离线训练 codebook,对数据分布有依赖,而且涉及大量非并行化的二分查找操作,在 GPU 上效率不高。
TurboQuant 的核心思路
TurboQuant 的做法很优雅:先对输入向量施加一个随机旋转矩阵,把任意分布转化成高维 Beta 分布。在高维空间中,旋转后的各坐标近似独立同分布,于是可以把复杂的多维向量量化问题拆解成一系列简单的一维标量量化问题。
 TurboQuant 在不同压缩比下的量化误差与信息论下界对比
TurboQuant 在不同压缩比下的量化误差与信息论下界对比
一维量化器的最优 codebook 可以预计算一次然后复用,所以运行时几乎没有额外开销。整个过程都是向量化操作,完美适配 GPU 并行架构。
解决内积偏差:不只是压得小
压缩 KV Cache 不是压了就完事 —— Transformer 的注意力机制依赖内积运算。单纯优化 MSE 的量化器在估计内积时会引入系统性偏差,1-bit 量化器在高维空间的乘法偏差可以达到 2/π。
TurboQuant 的解法是分两阶段:先用 (b-1) bit 做 MSE 最优量化,再用 1-bit QJL(Quantized Johnson-Lindenstrauss)变换处理残差。数学上可以证明内积估计是无偏的。
 在 Needle-In-A-Haystack 基准测试中,TurboQuant 4 倍压缩下保持 100% 检索准确率
在 Needle-In-A-Haystack 基准测试中,TurboQuant 4 倍压缩下保持 100% 检索准确率
实测:理论兑现了
在 Llama-3.1-8B-Instruct 和 Ministral-7B-Instruct 上的端到端测试:
- 4 倍压缩:Needle-In-A-Haystack 检索准确率 100%,与全精度持平,有效上下文长度达 104K tokens
- 量化误差:1-bit 时仅为信息论下界的 1.45 倍,接近理论最优
- 硬件友好:纯向量化运算,无需数据相关的 codebook 训练
这意味着你可以在同样的硬件上跑更长的上下文,或者用更便宜的硬件跑同样的任务。对于做 RAG、长文档分析、多轮对话的场景,这是实打实的成本优化。
为什么这很重要
模型压缩不是新话题,但 TurboQuant 的价值在于它同时满足了三个通常矛盾的目标:高压缩比、零精度损失、硬件高效。而且 data-oblivious 的特性意味着它可以直接集成到现有的推理引擎中,不需要针对每个模型或数据集做适配。
这类基础设施级别的优化,决定了 AI 应用的真实成本。当推理成本降下来,很多之前”不划算”的 AI 应用场景才会真正落地。
如果你在多个 AI 模型之间频繁切换测试推理效果,推荐试试 OfoxAI(ofox.ai)—— 一个账号搞定 Claude、GPT、Gemini 等主流模型,省去多平台来回切换的麻烦。
参考链接: