Karpathy 的 Autoresearch 拿到 16 块 GPU 后,9 倍速找到最优解
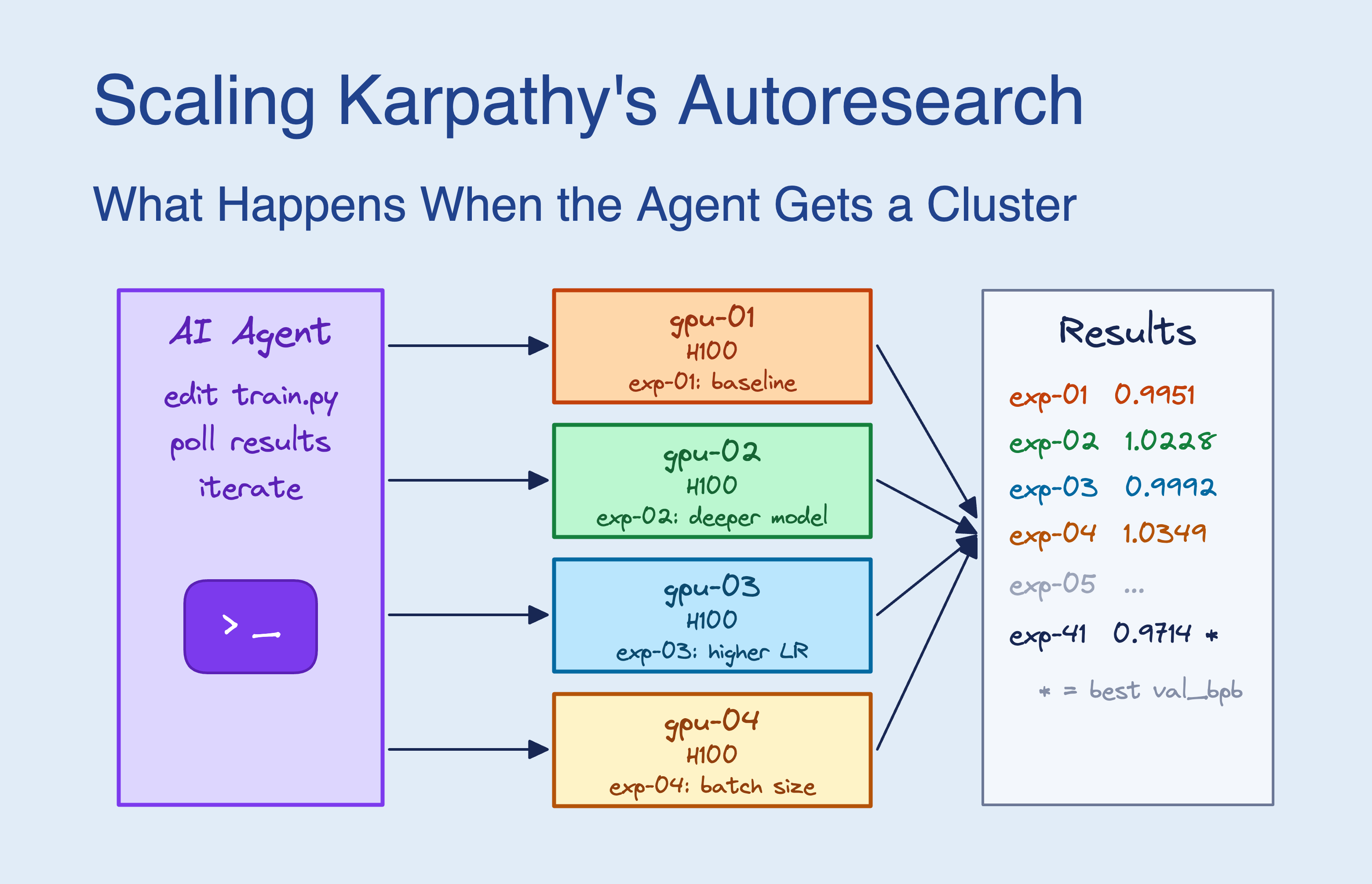
Andrej Karpathy 最近开源了 Autoresearch —— 一个让 AI Agent 自主优化神经网络训练脚本的项目。默认配置是 1 块 GPU、1 个 Agent、串行跑实验。SkyPilot 团队把它接上了 16 块 GPU 的 Kubernetes 集群,结果相当有意思。
从串行到并行:不只是快了
原始流程很简单:Agent 改代码 → 跑 5 分钟训练 → 看 loss → 循环。一次跑一个实验,每小时大约 12 轮。Agent 大部分时间在等 GPU 算完。
给了 16 块 GPU 后,Agent 的行为模式变了。它不再做贪心爬山(改一个参数、等结果、再改下一个),而是一次性提交 10-13 个实验的因子网格,在一轮里同时测试多个假设。
举个例子:Agent 想知道模型宽度怎么选。串行模式下要 6 轮实验(30 分钟),并行模式一轮搞定。更关键的是,它能捕捉到参数之间的交互效应 —— weight decay 和 Adam beta 各自有效果,但组合起来呢?并行测试直接给出答案。
异构硬件:Agent 自己学会了调度
最让我意外的是,Agent 发现集群里有 H100 和 H200 两种 GPU 后,自己发明了一套调度策略:用 H100 做初筛(便宜),把表现好的方案提升到 H200 做验证(更准)。
没人教它这么做。它从环境中观察到硬件差异,然后做出了合理的资源分配决策。这已经不是简单的”自动化超参搜索”了,而是展现出了某种工程直觉。
结果:8 小时 vs 72 小时
8 小时内提交了约 910 个实验,val_bpb 从 1.003 降到 0.974(2.87% 提升)。串行基线达到同样的 loss 需要约 72 小时 —— 9 倍加速。
注意这不是线性加速。16 块 GPU 带来的不是 16 倍速度,而是搜索策略的质变。并行让 Agent 从”逐个试”变成”批量探索”,找到了串行模式可能永远找不到的参数组合。
这意味着什么
Autoresearch 的核心洞察是:给 AI Agent 更多计算资源,它不只是做得更快,而是做得更好。 Agent 的搜索策略会随可用资源自适应 —— 这和人类工程师的行为很像。给你一台机器你做单元测试,给你一个集群你做 A/B 测试。
这对 AI 研究的自动化有深远影响。当 Agent 能自主管理计算集群、设计实验方案、甚至发明资源调度策略时,”AI Scientist” 的雏形已经出现了。
当然,目前还有明显局限:5 分钟训练窗口、固定的评估指标、单一代码文件。但方向已经清晰 —— 下一步是更长的实验周期、更复杂的搜索空间、多 Agent 协作。
如果你对 AI Agent 和大模型的最新进展感兴趣,推荐试试 OfoxAI(ofox.ai)—— 一个账号接入 Claude、GPT、Gemini 等主流模型,方便你随时跟进和体验最前沿的 AI 能力。