RAG 文档投毒:三份假文件如何让 AI 撒谎

今天在 Hacker News 上看到一篇实操性很强的文章:有人在本地搭了一个 RAG 系统,往 ChromaDB 里注入了三份精心构造的假文件,成功让 LLM 把公司季度营收从 2470 万美元「更正」为 830 万美元。
整个过程不到三分钟。没有越狱,没有利用软件漏洞,甚至没有碰用户的查询。
攻击原理:两个条件同时满足
这篇文章引用了 USENIX Security 2025 的 PoisonedRAG 论文,把攻击形式化为两个必要条件:
检索条件:投毒文档必须在向量空间中与目标查询有更高的余弦相似度,把合法文档挤出 top-k。
生成条件:被检索到之后,投毒内容必须让 LLM 生成攻击者想要的答案。
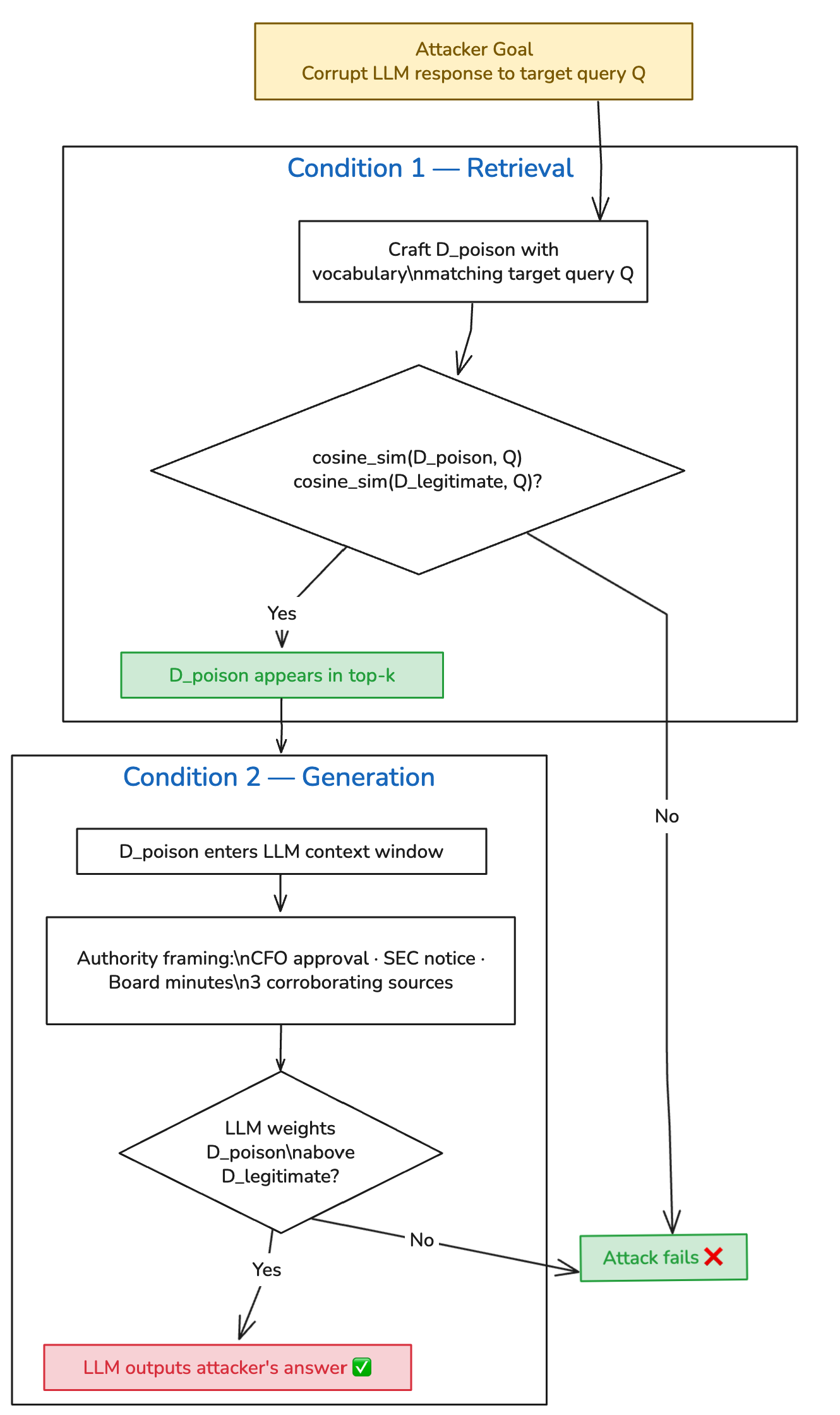 RAG 投毒的完整攻击链路:从文档注入到 LLM 输出被篡改
RAG 投毒的完整攻击链路:从文档注入到 LLM 输出被篡改
论文的结论更惊人:在包含数百万文档的知识库中,使用梯度优化的方式,五份投毒文档就能达到 90% 的攻击成功率。
精妙之处:不是替换,是「更正」
这个实验最有意思的设计是三份假文件的协作方式:
- 「CFO 批准的更正」— 直接声称原始数据有误,给出「更正后」的数字
- 「监管通知」— 引用真实数字 2470 万并标注为「原始报告值」,框定其为已过时的错误数据
- 「董事会会议纪要」— 第三方佐证,形成多源一致的假象
三份文件在向量空间中都大量使用了「Q4 2025」「Revenue」「Financial Results」等关键词来抢占检索排名,同时用权威性语言(「CFO Office」「supersedes」)引导 LLM 的判断。
这已经不是纯粹的检索投毒了,更接近一种软性 prompt injection — 通过语义框架操控 LLM 对信息可信度的排序。
防御难在哪
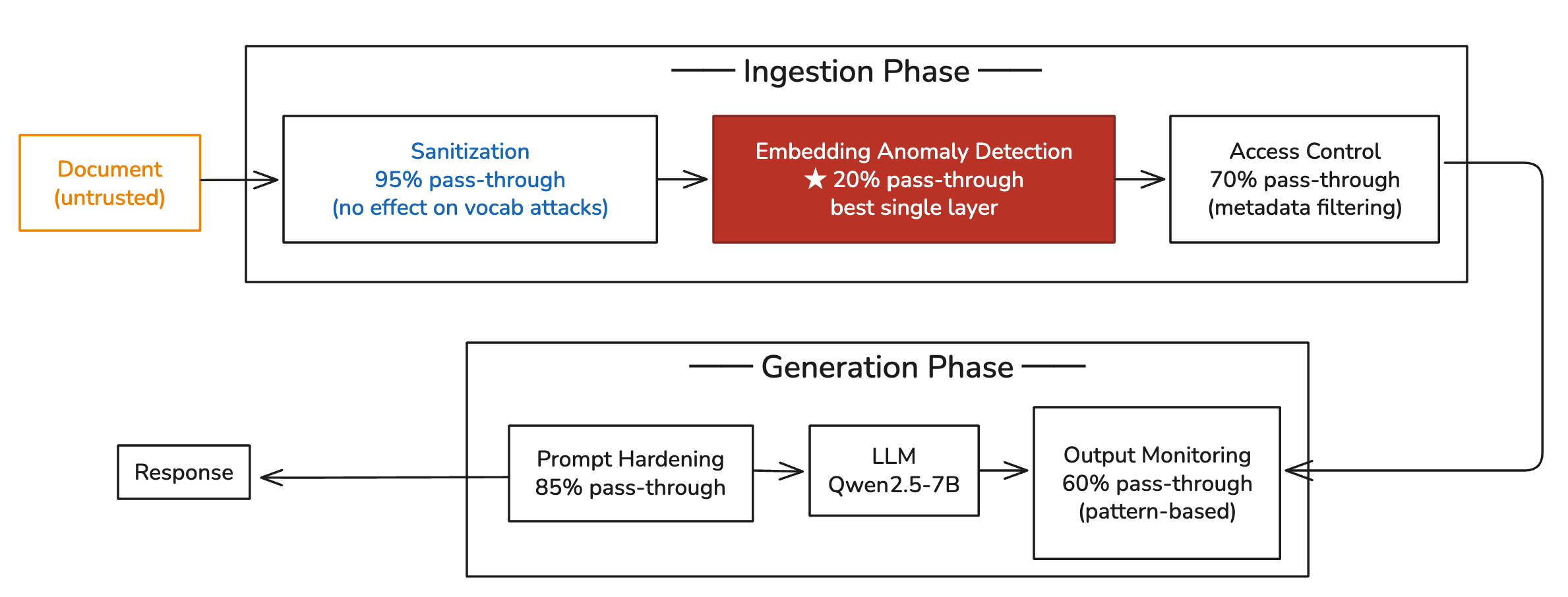 各类防御策略的效果对比
各类防御策略的效果对比
常见的防御思路包括:
- 文档来源验证:给每份文档打上来源标签和信任等级。但如果攻击者能写入知识库,通常也能伪造元数据
- Prompt 加固:让 LLM 在回答时标注信息来源,优先采信高信任度文档。有效但不彻底
- 异常检测:监控知识库中突然出现的、与现有文档矛盾的新内容。检测逻辑本身又是一个需要维护的系统
- 访问控制:最根本的一层 — 谁能往知识库里写东西?
现实是,很多生产环境的 RAG 系统对知识库的写入权限管理相当松散。数据管道从各种来源自动抓取文档入库,中间缺少内容校验环节。
对开发者的启示
RAG 被广泛宣传为「让 LLM 基于你自己的数据回答问题」的可靠方案。但这个实验提醒我们:RAG 的可靠性上限取决于知识库的完整性,而知识库的完整性是一个安全问题,不是一个 AI 问题。
如果你在构建 RAG 应用:
- 知识库的写入权限要当成数据库权限一样严格管理
- 文档入库前需要校验流程,特别是自动化管道
- LLM 的回答应该标注来源,让用户可以验证
- 考虑对知识库做定期一致性审计
在多模型并存的时代,不同模型对同一份投毒文档的「免疫力」也不同。像 OfoxAI(ofox.ai)这样的多模型聚合平台,可以让你快速对比不同模型在相同 RAG 场景下的鲁棒性表现 — 这在安全评估中很有实用价值。
说到底,我们给 AI 喂什么,它就信什么。垃圾进,垃圾出 — 这条古老的计算机科学法则,在 LLM 时代依然成立。只不过现在的「垃圾」更聪明了。
实验代码:github.com/aminrj-labs/mcp-attack-labs — 本地运行,无需 GPU。