QMD — Shopify CEO 开源的本地文档搜索引擎,给 AI Agent 的记忆层
AI Agent 越来越能干,但有一个问题始终没被优雅地解决——记忆。
你让 Claude 帮你梳理项目架构,它不知道你上周的会议纪要里已经讨论过方案 A 被否决了;你让 Cursor 重构一段代码,它不知道你的技术文档里有一套命名规范。Agent 缺的不是推理能力,而是检索能力——在你的私有知识库里快速找到相关上下文的能力。
最近,Shopify CEO Tobi Lütke 开源了一个项目 QMD(Query Markup Documents),恰好瞄准了这个问题。上线不久就拿到了 7000+ stars。我花了一些时间读了它的源码和架构设计,觉得值得聊一聊。
QMD 是什么
 来源:素材原文
一句话总结:一个完全本地运行的混合搜索引擎,专为文档、笔记和知识库设计,可以直接接入 AI Agent 工作流。
来源:素材原文
一句话总结:一个完全本地运行的混合搜索引擎,专为文档、笔记和知识库设计,可以直接接入 AI Agent 工作流。
你可以把你的 Markdown 笔记、会议纪要、项目文档甚至代码注释都丢给它索引,然后用关键词或自然语言去搜索。它不依赖任何云端服务,所有的 embedding 生成、搜索排序、LLM 重排序都在你的机器上完成。
用法很直觉:
1
2
3
4
5
6
7
8
9
10
11
# 创建 collection 索引你的文档目录
qmd collection add ~/notes --name notes
qmd collection add ~/Documents/meetings --name meetings
# 生成 embedding
qmd embed
# 搜索
qmd search "project timeline" # 关键词搜索
qmd vsearch "how to deploy" # 语义搜索
qmd query "quarterly planning" # 混合搜索 + 重排序(最高质量)
三种搜索模式覆盖了不同场景:search 走 BM25 全文检索,速度快;vsearch 走向量语义检索,理解意图;query 则是完整的混合搜索 pipeline,质量最好但也最慢。
技术架构:一条精心设计的搜索 Pipeline
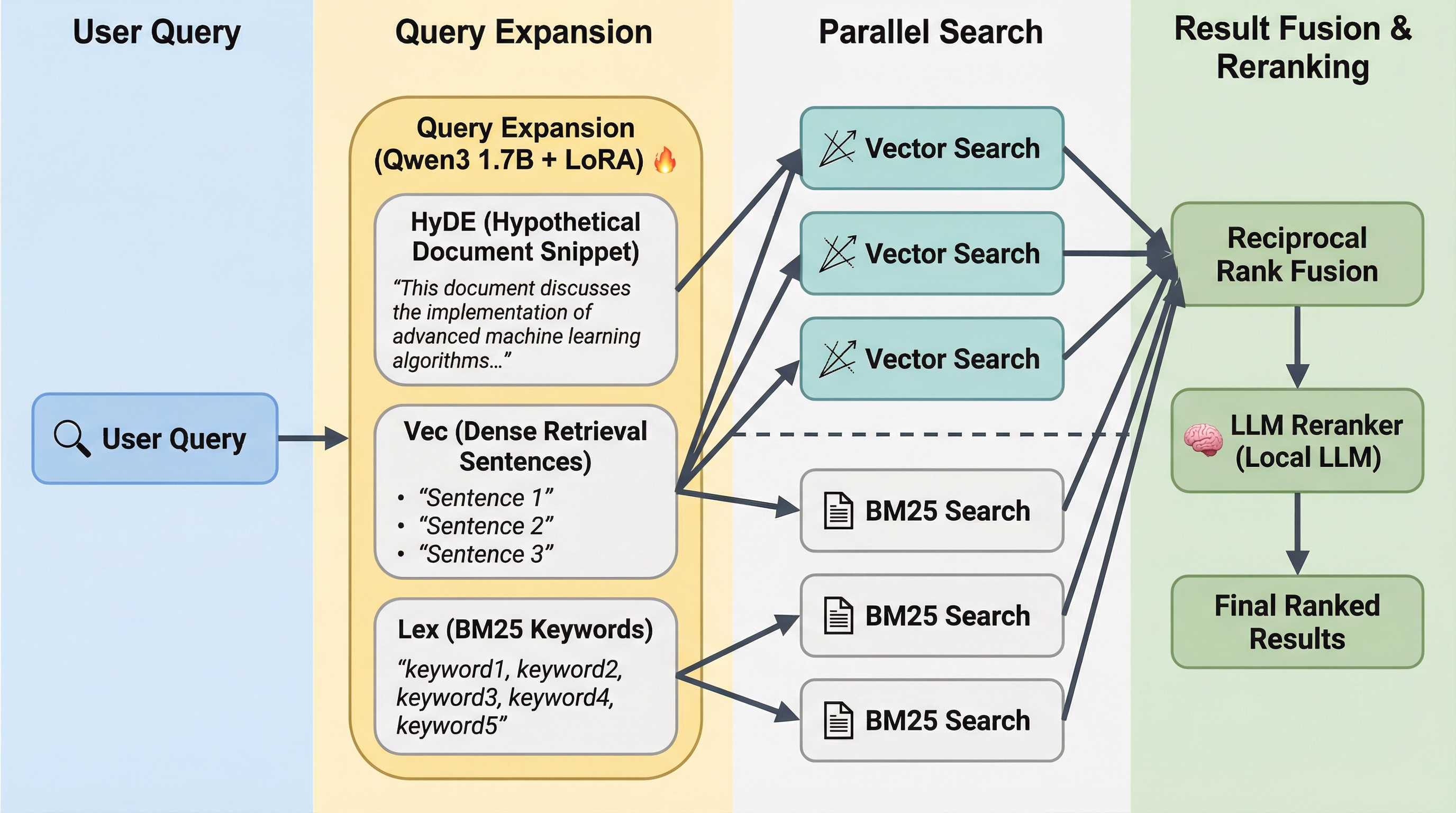
QMD 的架构设计是它最值得关注的部分。这不是一个简单的 “embedding + cosine similarity” 的 demo,而是一条完整的、参考了业界最新实践的混合搜索管线。
整个 query 模式的流程如下:
1. Query Expansion(查询扩展)
用户的原始查询首先被送入一个 fine-tuned 的小模型(qmd-query-expansion-1.7B),生成 2 个语义相近但表述不同的变体查询。原始查询会被赋予 2 倍权重——这是一个聪明的设计,既利用了查询扩展带来的召回率提升,又避免了扩展查询”喧宾夺主”。
2. BM25 + Vector 并行检索
每个查询(原始 + 扩展)同时走两条路:BM25 全文搜索(基于 SQLite FTS5)和向量语义搜索(基于 embeddinggemma-300M 模型)。对于 3 个查询,这意味着 6 路并行检索。
3. RRF Fusion(倒排融合)
所有检索结果通过 Reciprocal Rank Fusion 融合:score = Σ(1/(k+rank+1)),其中 k=60。这是一个经典的多路召回融合策略,不依赖于原始分数的绝对值,只看排名。此外还有一个细节——在任意检索列表中排名第 1 的文档会获得 +0.05 的 bonus,排名 2-3 获得 +0.02。这保证了精确匹配不会被稀释。
4. LLM Re-ranking(重排序)
取 Top 30 候选文档,送入 qwen3-reranker-0.6b 模型进行重排序。模型对每个文档给出 Yes/No 判断并通过 logprobs 输出置信度分数。
5. Position-Aware Blending(位置感知混合)
最后一步很精妙:不是简单地用 reranker 分数覆盖 RRF 分数,而是根据文档在 RRF 中的原始排名来决定两者的混合比例。Top 1-3 保留 75% 的 RRF 权重,Top 4-10 保留 60%,Top 11+ 则让 reranker 占主导(60%)。这样做的逻辑是:排名靠前的文档大概率已经是精确匹配了,不需要 reranker 来”纠正”,而排名靠后的长尾结果则更需要语义理解来甄别。
整套 pipeline 用 TypeScript 实现,通过 node-llama-cpp 在本地加载 GGUF 格式的模型。三个模型加起来大约 2GB,对于现在的开发机来说完全不是问题。
与 AI Agent 的集成
QMD 原生支持 MCP(Model Context Protocol)Server,这意味着它可以直接接入 Claude Desktop、Claude Code 等支持 MCP 的 AI 工具。配置非常简单:
1
2
3
4
5
6
7
8
{
"mcpServers": {
"qmd": {
"command": "qmd",
"args": ["mcp"]
}
}
}
配置完成后,Agent 就多了几个工具:qmd_search、qmd_vsearch、qmd_query、qmd_get、qmd_multi_get 和 qmd_status。当你跟 Claude 说”帮我找找上周关于数据库迁移的讨论”,它会自动调用 QMD 去搜索你的会议纪要,拿到相关上下文后再回答你。
同时,QMD 的 CLI 输出也针对 Agent 做了优化——--json 输出结构化数据,--files 输出文件列表,--min-score 可以过滤低相关度结果。即便不走 MCP,Agent 直接通过命令行调用也很方便。
这个思路其实揭示了一个趋势:AI Agent 的能力边界不是由模型决定的,而是由它能访问到的工具和数据决定的。 QMD 做的事情,本质上是给 Agent 装了一个”长期记忆模块”。
我的思考
Local-first 为什么重要
把文档搜索放到云端容易得多——调一个 embedding API,存到 Pinecone,搜索走 API。但对于个人知识库和企业内部文档来说,这条路有几个硬伤:
- 隐私。会议纪要、内部文档、个人笔记,你真的想把这些上传到第三方?
- 延迟。Agent 工作流中搜索是高频操作,每次都走网络请求,延迟会严重拖慢体验。
- 成本。Embedding API 和向量数据库都是按量计费的,文档多了之后成本不低。
- 离线可用。在飞机上、在没网的场景下,云端搜索就废了。
QMD 选择全本地运行是一个正确的方向。随着端侧模型能力不断提升,”在本地跑一个够用的小模型”已经完全可行。300MB 的 embedding 模型、600MB 的 reranker,都不是什么重量级的东西。
搜索质量的工程细节
QMD 在搜索 pipeline 上做的那些细节——query expansion 的权重控制、RRF 的 top-rank bonus、position-aware blending——看起来不起眼,但这些恰恰是把搜索做到”好用”的关键。任何一个做过搜索系统的工程师都知道,从”能搜出来”到”搜出来的都是你想要的”之间,差的就是这些工程细节。
Tobi 在 README 里写的设计理念是 “Tracking current sota approaches while being all local”,我觉得他做到了。这条 pipeline 基本上把学术界近几年在混合搜索、查询扩展和重排序方面的最佳实践都落地了,而且全程不依赖云端。
还有什么可以期待
目前 QMD 主要面向 Markdown 文档。如果未来能支持更多格式(PDF、HTML、代码文件),以及增量索引和实时文件监听,实用性会再上一个台阶。另外,collection 级别的权限和搜索范围控制,对于团队场景也很有价值。
结论
QMD 解决的问题不大,但解决得很漂亮。它不是又一个”用 LLM 做 XX”的概念验证,而是一个工程上精心打磨过的、能直接用起来的工具。
如果你正在用 Claude Code 或类似的 AI Agent 工具写代码、做研究、整理知识,QMD 值得一试。给你的 Agent 一个搜索你私有文档的能力,你会发现它变得有用很多。
毕竟,一个没有记忆的 Agent,跟一个每天都失忆的同事没什么区别。
1
bun install -g github:tobi/qmd
试试看。
🔧 想给 AI Agent 接入更强的模型? OfoxAI 提供一站式 AI API 接入,支持 Claude、GPT 等主流模型,让你的 Agent 工作流如虎添翼。首次充值输入优惠码
OFOXAI2026享 8 折优惠,使用推荐码AFF_KOGPMT还可获得 $3.00 免费 Credits。