Mistral Forge:企业级 AI 的下一个战场不是模型,是数据

Mistral AI 这两天放了个大招 — Forge,一个让企业在自己的私有数据上训练 frontier 级别模型的系统。HN 上 700+ 点,讨论热度很高。
这件事值得聊聊,因为它触及了一个行业拐点:通用大模型的天花板已经近了,下一轮竞争在企业私有知识上。
Forge 是什么
简单说,Forge 让企业把自己的内部文档、代码库、合规政策、运营流程等私有数据喂给 Mistral 的模型,训练出一个「懂你」的专属模型。
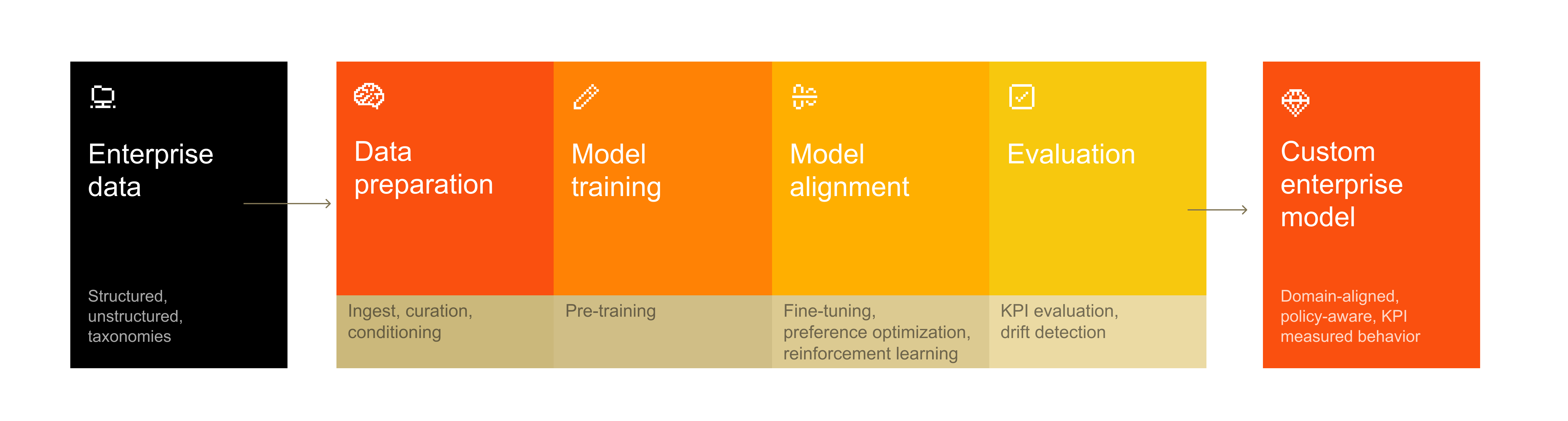 Mistral Forge 支持从预训练到强化学习的完整训练链路
Mistral Forge 支持从预训练到强化学习的完整训练链路
它覆盖三个阶段:
- Pre-training:在大规模内部数据集上构建领域感知模型
- Post-training:针对特定任务和环境微调行为
- Reinforcement Learning:让模型/Agent 对齐内部策略,提升工具调用和决策能力
首批合作方包括 ASML、爱立信、欧洲航天局、新加坡 DSO 等 — 都是对数据主权和合规有硬性要求的组织。
为什么这件事重要
过去两年,AI 行业的叙事是「模型越大越强」。但现实是:
1. 通用模型在专业领域撞墙了
GPT-4、Claude、Gemini 在通用任务上已经很强,但扔给它们一份芯片制造工艺文档或航天器故障诊断手册,表现会断崖式下降。不是模型不够聪明,是训练数据里压根没有这些东西。
2. RAG 不是银弹
很多企业在用 RAG(检索增强生成)来弥补这个gap。但 RAG 本质上是「开卷考试」— 模型并没有真正理解你的领域知识,只是在检索结果里找答案。对于需要深度推理的场景,这远远不够。
3. 数据主权是硬约束
欧洲企业、政府机构、国防单位 — 他们的数据根本不能送到第三方 API。Forge 提供的是在自己控制范围内训练和部署的能力,这对合规敏感的行业是刚需。
冷静看:风险和局限
别急着兴奋,几个问题需要想清楚:
训练成本。在私有数据上做 pre-training 或 RL,算力开销不是小数目。Mistral 没公布定价,但参考行业水平,这不是中小企业玩得起的。
数据质量。垃圾进垃圾出。企业内部数据的质量参差不齐 — 过时的文档、矛盾的规范、未清理的日志。没有好的数据治理,Forge 也救不了你。
评估难题。通用 benchmark 衡量不了企业专属模型的效果。你需要自己建评估体系,这本身就是一项重工程。
行业趋势
Mistral 不是第一个做这件事的。OpenAI 有 fine-tuning API,Google 有 Vertex AI,但 Forge 的定位更激进 — 它不只是微调,而是从预训练阶段就介入。这意味着更深的定制化,也意味着更高的门槛。
我的判断:未来 2 年,「通用模型 + 企业专属层」会成为标配架构。 通用模型负责基础能力,企业专属层负责领域知识和合规对齐。谁能把这个训练流程做得更简单、更可控,谁就能拿下企业市场。
Mistral 选择从欧洲市场切入是聪明的 — 欧洲对数据主权的要求最严格,愿意为合规付费的企业也最多。
对开发者来说,不管你用的是 Mistral、Claude 还是 GPT,保持对多个模型的熟悉度越来越重要。如果你需要在不同模型之间快速切换对比,可以试试 OfoxAI(ofox.ai)— 一个账号接入主流模型,在技术路线分化的时代保持选择权。