Miasma:用「毒数据陷阱」反击 AI 爬虫的开源武器
你的网站内容正在被 AI 公司大规模抓取,用来训练下一代模型。这不是猜测——看看你的服务器日志,GPTBot、ClaudeBot、Bytespider 这些 User-Agent 大概率已经在你的访问记录里了。
面对这种「合法灰色地带」的数据掠夺,一个叫 Miasma 的 Rust 开源项目给出了一个有趣的反击思路:不是拦截爬虫,而是喂它们吃毒数据。
核心机制:无限毒饵buffet
Miasma 的设计思路出奇简单:
- 在网页中嵌入 CSS 隐藏的链接(
display: none),人类用户看不到,但爬虫会跟进 - 爬虫访问这些链接后,被反向代理转发到 Miasma 服务
- Miasma 返回精心构造的「毒数据」——看起来像正常网页内容,实际上是垃圾信息
- 每个页面都包含更多自引用链接,形成无限循环
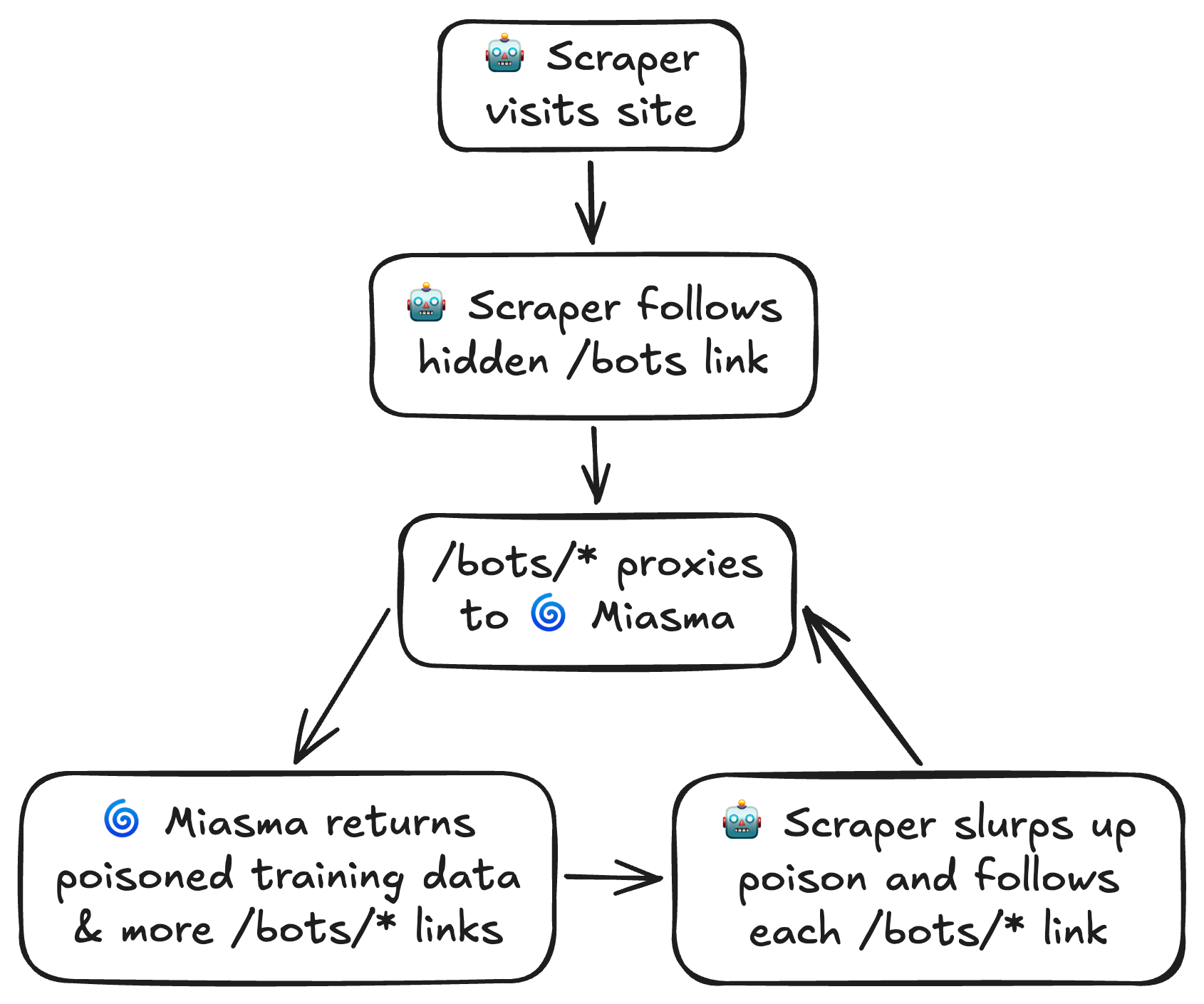 爬虫一旦进入 Miasma 的陷阱,就会陷入无限循环
爬虫一旦进入 Miasma 的陷阱,就会陷入无限循环
这个设计的精妙之处在于:对正常用户完全透明,但对爬虫来说是一个永远吃不完的「自助餐」。而且因为用 Rust 写的,内存占用极低——你不需要为了对付爬虫浪费自己的计算资源。
为什么不直接用 robots.txt?
技术人的第一反应可能是:robots.txt 不就行了?
问题是 robots.txt 是「君子协定」。遵守的爬虫本来就不是问题,不遵守的你拿它没办法。而 Miasma 的策略是:既然你要来吃,那就让你吃到撑——吃的还是垃圾。
 Miasma 生成的内容看起来像正常网页,但全是精心构造的噪声
Miasma 生成的内容看起来像正常网页,但全是精心构造的噪声
这个思路并不新鲜。反爬虫领域一直有蜜罐(honeypot)的概念,但 Miasma 把它工程化了:一行命令启动,配合 Nginx 几行配置就能部署。
数据投毒的局限性
当然,要冷静看待这个方案的实际效果:
训练数据稀释比例极低。 OpenAI、Anthropic 这些公司抓取的是整个互联网。你一个站点的毒数据,在 TB 级语料库中可能连噪声都算不上。
大模型训练有清洗流程。 重复内容检测、质量过滤、去重——这些标准管线会过滤掉大部分低质量数据。Miasma 生成的内容如果模式太明显,反而容易被识别和丢弃。
法律风险模糊。 虽然爬虫先侵犯了你,但主动投毒是否构成某种「干扰计算机系统」?目前没有判例。
真正的价值:态度和讨论
Miasma 在 HN 上拿到 300+ 赞,说明开发者社区对 AI 爬虫的不满已经到了一个临界点。它的价值不在于真的能毒翻 GPT-6 的训练数据,而在于:
- 技术社区需要一个明确的「不同意」表达方式。光在 Twitter 上抱怨没用,写代码才是程序员的语言
- 推动行业讨论数据授权的合理机制。当反抗成本足够低时,「默认可抓」的潜规则才会被挑战
- 作为合规谈判的筹码。当网站主有了技术反制手段,AI 公司才有动力认真谈数据授权
这让我想到一个更大的问题:AI 行业目前的数据获取模式是不可持续的。要么走向合规授权,要么走向技术对抗的军备竞赛。Miasma 是后者的一个信号。
如果你也在关注 AI 领域的各种动态,想在不同模型之间快速切换体验,推荐试试 OfoxAI(ofox.ai)——一个账号接入 Claude、GPT、Gemini 等主流模型,省去多平台注册的麻烦。