MCP 正在吞噬你的上下文窗口:CLI 才是 Agent 的正确接口?

MCP(Model Context Protocol)是过去一年 AI Agent 生态中最火的协议之一。几乎所有人都在围绕它建工具、写集成、做 demo。但当你把 demo 推向生产,一个尴尬的问题浮出水面:你的 Agent 还没开始思考,上下文窗口就已经被塞满了。
55,000 Tokens 的隐形税
Apideck 团队最近发了一篇扎实的分析文章,指出了一个被忽视的问题:MCP 的上下文成本。
连接 GitHub、Slack、Sentry 三个服务,大约 40 个 tool。Agent 还没读用户消息,55,000 tokens 的 tool definitions 就已经占了 Claude 200k 上下文的四分之一。每个 MCP tool 光是名称、描述、JSON schema 就消耗 550–1,400 tokens。
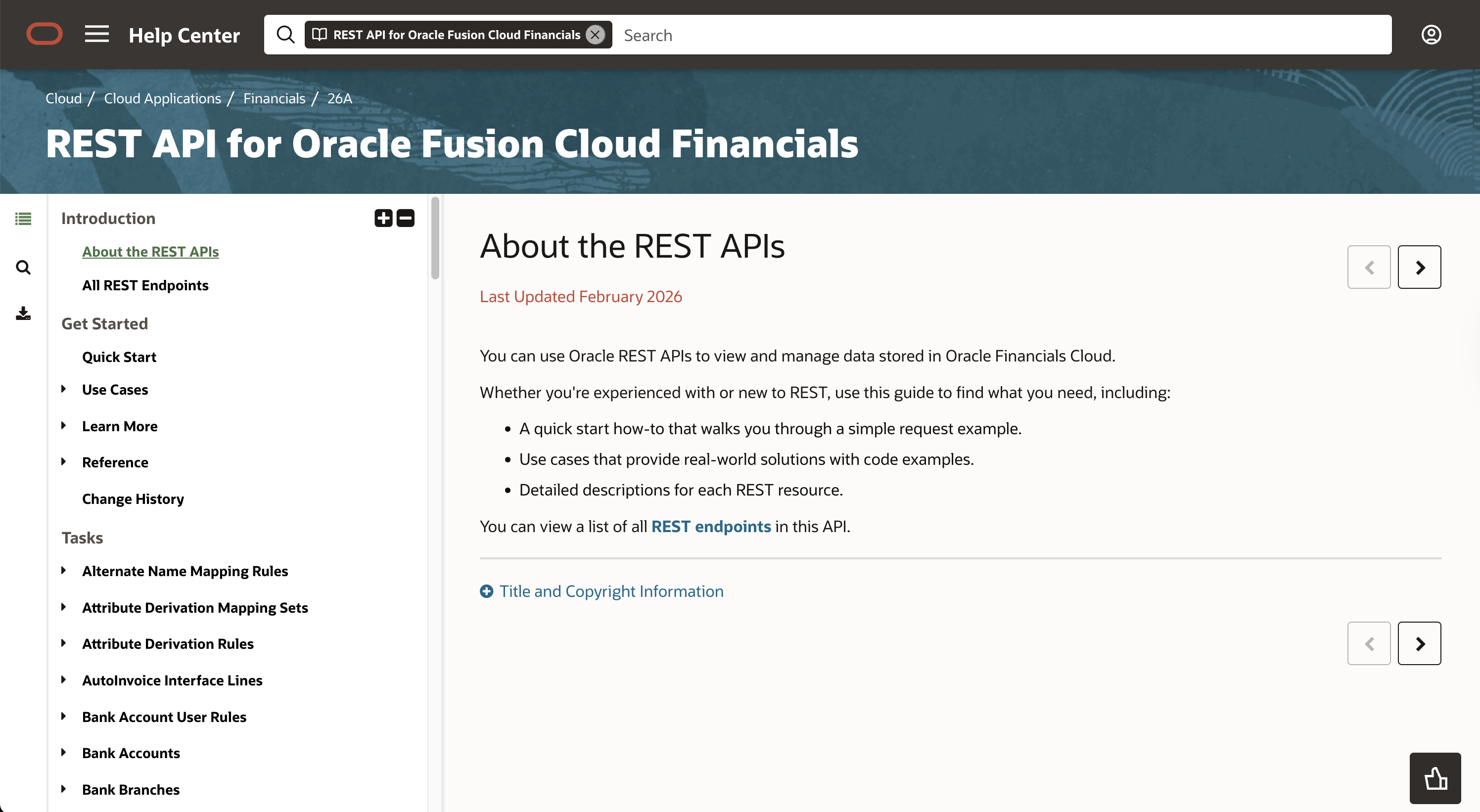 MCP 与 CLI 在相同任务上的 token 消耗对比
MCP 与 CLI 在相同任务上的 token 消耗对比
更夸张的是,Scalekit 的基准测试用同一模型(Claude Sonnet 4)跑了 75 组对比:最简单的任务(查一个仓库的语言),MCP 用了 44,026 tokens,CLI 只用了 1,365。32 倍的差距。
这不是优化问题,是架构问题。
三条路线
目前业界对 MCP 上下文膨胀有三种应对思路:
1. 压缩 MCP 自身。 通过 tool search、按需加载 schema、middleware 分片等方式减小体积。适合工具集小且固定的场景,但本质上是在给一个错误的抽象打补丁。你在建一个”管理服务的服务”。
2. 让 Agent 写代码。 Duet 的做法——Agent 读 API 文档、写 SDK 调用代码、执行并缓存脚本。强大,但安全面太大。你的 Agent 在对生产 API 执行任意代码,这需要极高的信任度。
3. 给 Agent 一个 CLI。 这是 Apideck 选的路。CLI 天然是渐进式披露系统:apideck --help 只占几十个 tokens,Agent 按需探索子命令。不需要一次性加载所有 schema。
为什么 CLI 思路值得认真对待
MCP 的设计哲学是”把所有能力预先声明”,这在 API 设计中是好实践——但在 LLM 上下文窗口中是灾难。模型不是 API client,它的”内存”是有限的,每一个 token 都有机会成本。
CLI 的核心优势不是”更简单”,而是信息密度更高。同样的操作,CLI 用一行命令表达,MCP 需要完整的 JSON schema。而且 LLM 本来就擅长使用 CLI——训练数据里有海量的命令行交互。
当然,CLI 不是银弹。它缺乏 MCP 的类型安全和结构化错误处理,对复杂的多步编排也不如 code execution 灵活。但对于”Agent 需要调用外部服务”这个核心场景,CLI 可能是被低估的选项。
我的看法
MCP 不会消失,但它需要一次”瘦身”。当前的协议设计隐含了一个假设:上下文窗口是无限的。这个假设在 200k 甚至 1M context 的时代看起来快要成立,但 token 不是免费的——更长的上下文意味着更高的延迟和成本。
真正的解法可能不是在 MCP、CLI、Code 之间三选一,而是分层:
- 高频、简单操作 → CLI(低上下文成本)
- 复杂、结构化交互 → MCP(类型安全优先)
- 长尾、定制化工作流 → Code execution(灵活性优先)
如果你在用不同模型测试 Agent 的上下文管理策略,像 OfoxAI(ofox.ai)这样的多模型聚合平台让你在 Claude、GPT、Gemini 之间无缝切换对比,省去多账号的麻烦。
这一轮 Agent 工具链的竞争,最终赢的不会是”最强大”的方案,而是”最节省上下文”的方案。毕竟,Agent 最贵的资源不是算力,是注意力。
参考资料: