llmfit:让大模型自动适配你的硬件,本地跑 LLM 不再靠猜
本地跑大模型最头疼的事情是什么?不是安装环境,不是下载权重——是选模型。
你的机器有 16GB 内存、一张 8GB 显存的显卡,应该跑 7B 还是 13B?量化用 Q4 还是 Q8?上下文长度设多少不会 OOM?这些问题没有标准答案,大多数人靠的是试错和社区经验贴。
今天在 Hacker News 上看到一个叫 llmfit 的开源工具,思路很直接:自动检测你的硬件配置,然后推荐最合适的模型和参数。
解决的痛点
 来源:素材原文
本地部署 LLM 的典型流程是这样的:
来源:素材原文
本地部署 LLM 的典型流程是这样的:
- 看到某个模型效果不错,想本地跑
- 查系统配置:多少 RAM、GPU 显存多大、CPU 啥架构
- 去社区搜「XX 显卡能跑 XX 模型吗」
- 下载、启动、发现要么 OOM 要么慢得离谱
- 换一个量化版本,重复 3-4
这个过程对老手来说是肌肉记忆,但对大多数开发者来说是纯粹的时间浪费。llmfit 要做的就是把步骤 2-4 自动化。
实现思路
llmfit 的逻辑并不复杂:
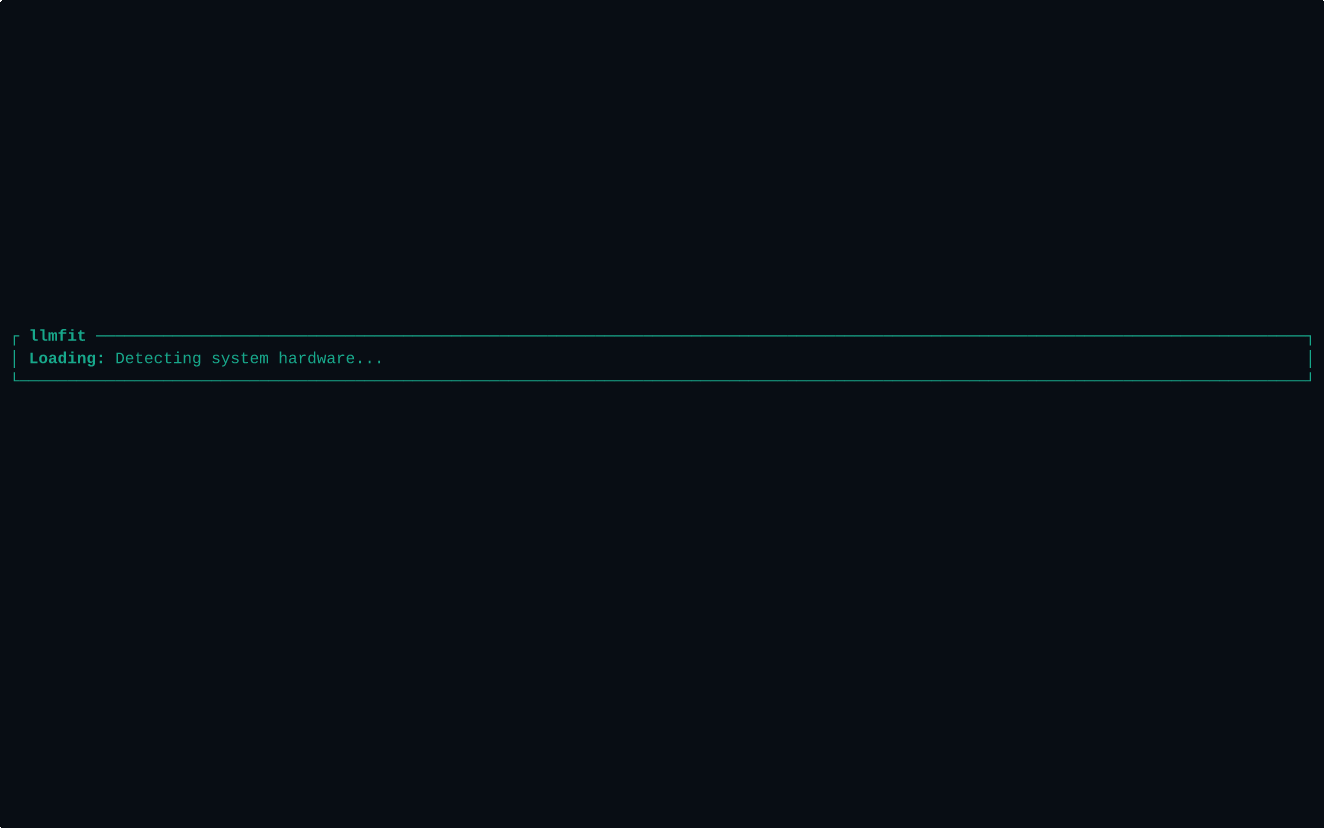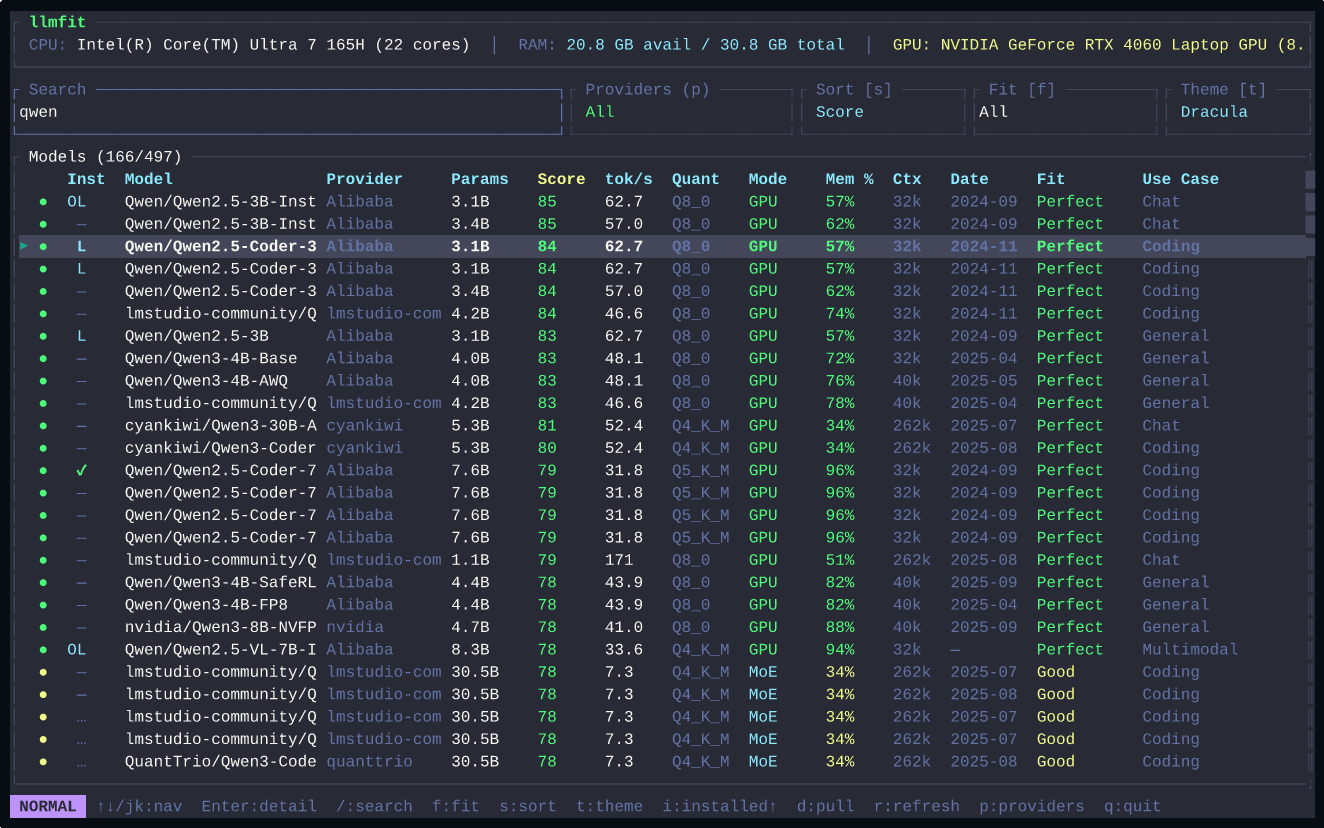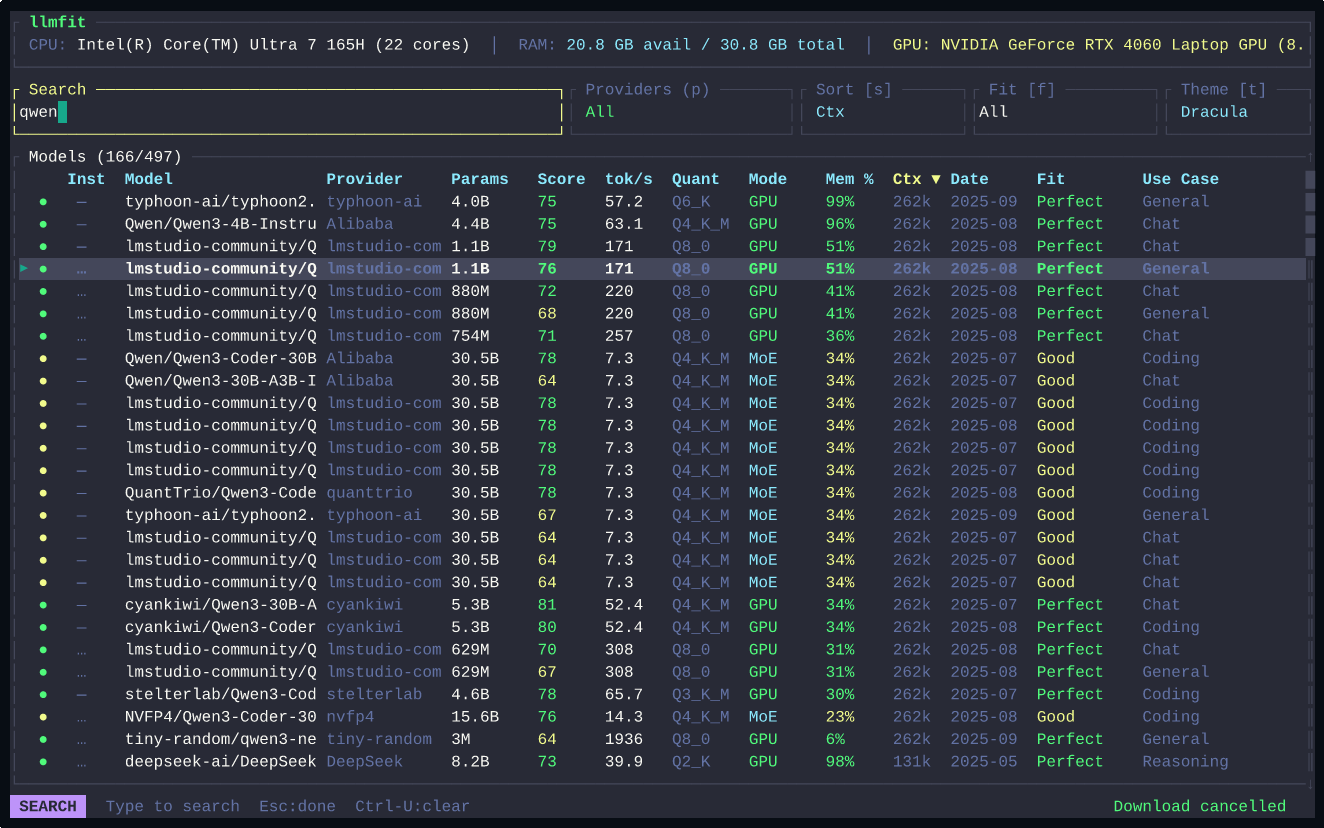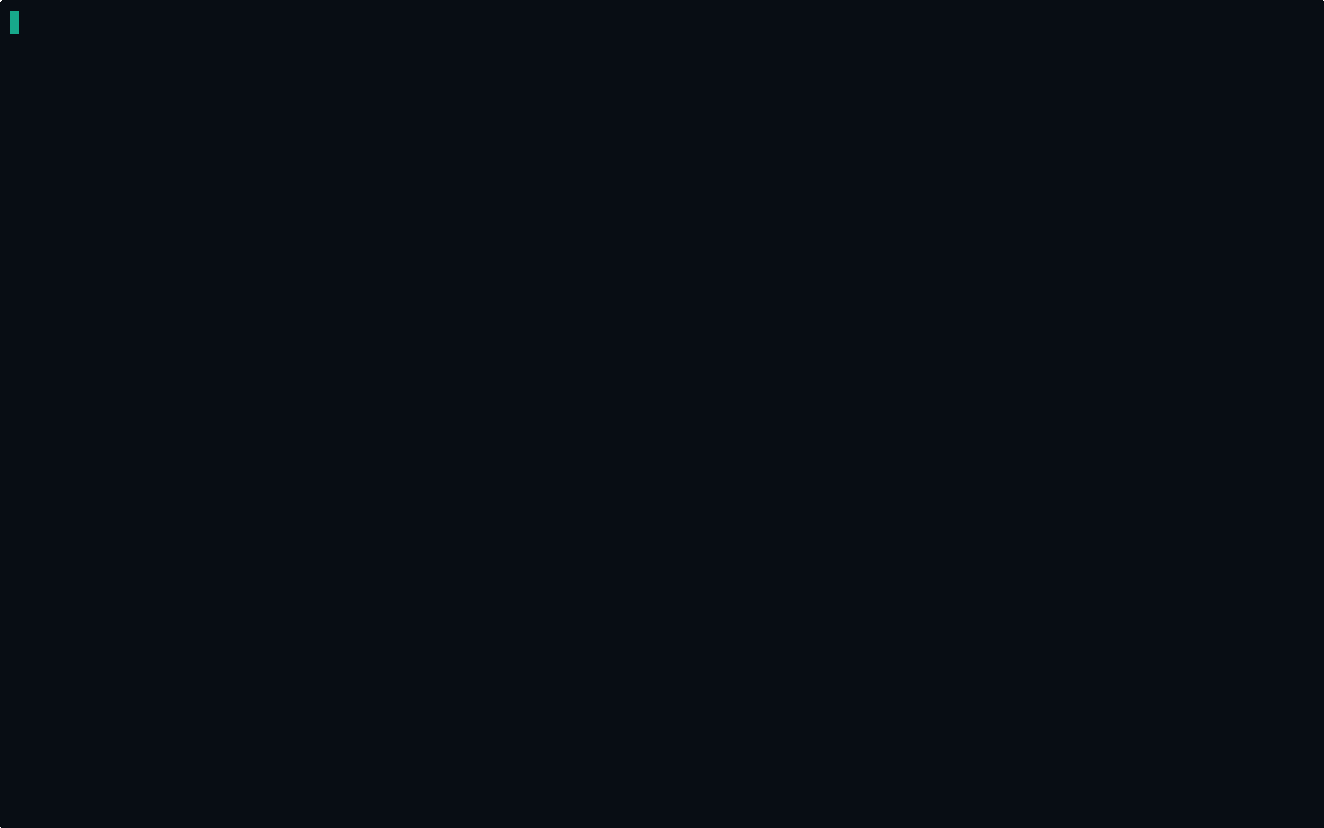
- 硬件探测:读取系统的 RAM、CPU 核心数/架构、GPU 型号和显存
- 模型匹配:根据硬件参数,从已知的模型库中筛选出能跑、跑得动、跑得好的选项
- 参数推荐:包括量化级别、上下文窗口大小、batch size 等关键配置
本质上是把社区里散落的「XX 显卡跑 XX 模型」的经验,结构化成了一套规则引擎。
为什么这件事有价值
表面上这只是个小工具,但它指向一个更大的趋势:本地 AI 的易用性正在成为瓶颈。
过去两年,开源模型的能力飙升。Llama 3、Mistral、Qwen 2.5,7B 参数的模型已经能胜任很多实际任务。硬件门槛也在降低——M 系列 Mac 的统一内存让本地推理变得可行,消费级 GPU 的显存也在涨。
但「能跑」和「好用」之间还有一道鸿沟。这道鸿沟不是技术问题,而是信息匹配问题——用户不知道自己的硬件最适合什么模型,什么配置能达到最佳性价比。
llmfit 这类工具填的就是这个缝隙。
局限性
当然,自动推荐不可能完美:
- 模型更新太快:每周都有新模型发布,规则库能不能跟上是个问题
- 使用场景差异大:同样的硬件,跑代码补全和跑长文本生成对资源的需求完全不同
- 量化不是万能的:低精度量化省显存但损失质量,这个 trade-off 因任务而异
理想的方案可能是:不只推荐模型,还跑一轮快速 benchmark,用实际数据告诉你「这个配置下,XX 模型的推理速度是 XX tokens/s,质量评分 XX」。
更大的图景
本地 LLM 和云端 API 不是二选一的关系。实际开发中,很多团队的策略是:隐私敏感、低延迟的任务走本地,复杂推理、长上下文的任务走云端。
这意味着开发者需要同时管理本地模型和云端 API。本地用 llmfit 选模型,云端在多个服务商之间挑性价比——两边都是信息匹配问题。
工具链正在慢慢补齐这些缺口,本地推理的体验会越来越接近「开箱即用」。而当本地搞不定的时候,云端多模型的灵活切换同样重要——毕竟不同任务适合不同模型,能低成本地在 Claude、GPT、Gemini 之间按需选择,才是效率最高的工作方式。
如果你也在多个云端模型之间频繁切换,可以看看 OfoxAI(ofox.ai),一个账号聚合主流大模型,免去多平台注册管理的麻烦。