Claude Opus 4.8 的升级,不在参数,而在协作方式

Anthropic 在 2026 年 5 月 28 日发布了 Claude Opus 4.8。表面上看,这是一次常规版本迭代;但如果你把它放进真实的开发流程里看,会发现这次更新的重点不是“再刷几个 benchmark 分数”,而是把模型往“更可靠的协作者”方向推了一格。
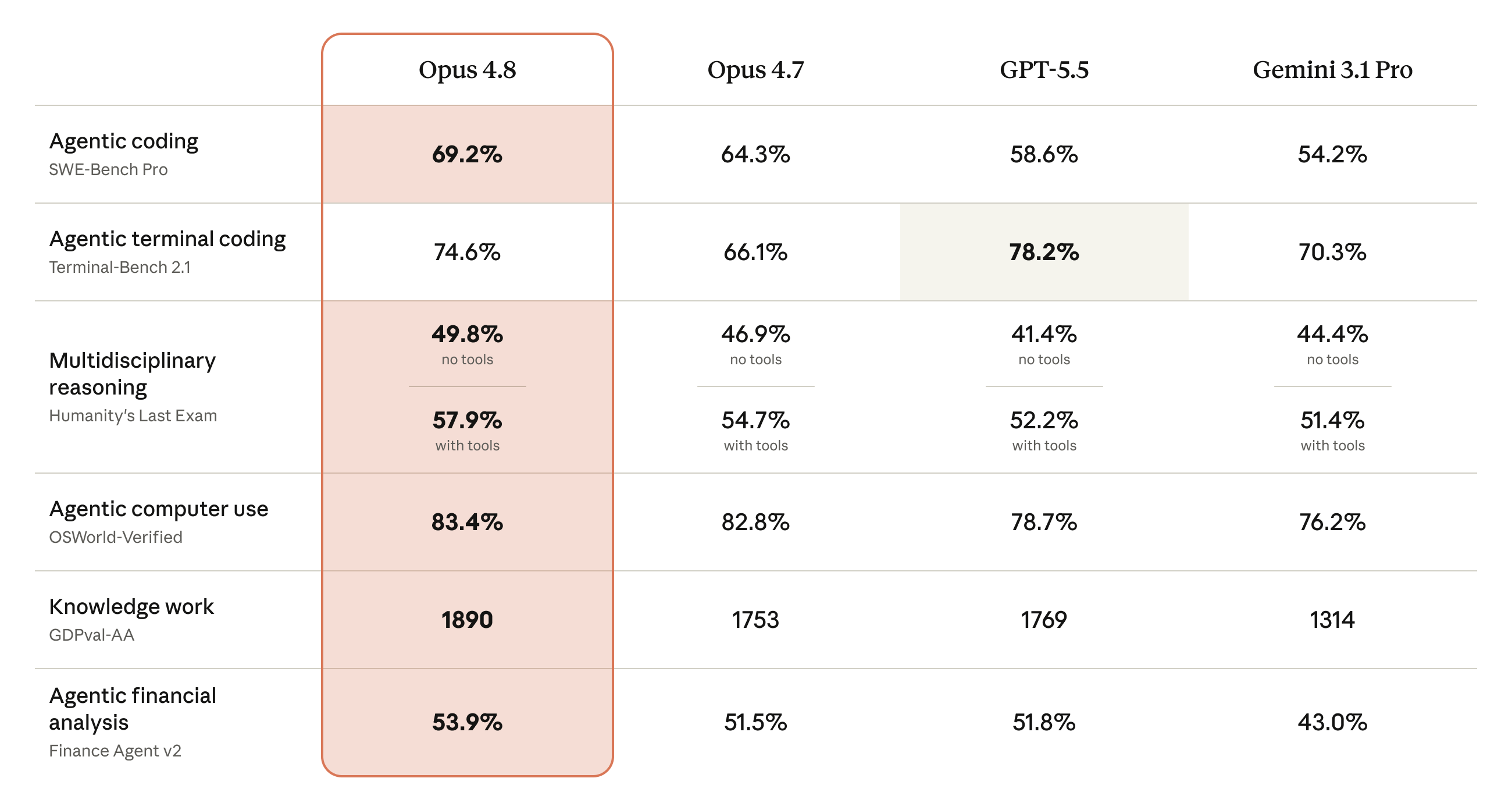 Claude Opus 4.8 的官方能力图,重点不只是编码和推理分数,而是长任务中的稳定性。
Claude Opus 4.8 的官方能力图,重点不只是编码和推理分数,而是长任务中的稳定性。
这次升级,核心是“可控”
Anthropic 的官方描述很直接:Opus 4.8 是对 Opus 系列的一次升级,重点提升了 coding、agentic tasks 和 professional work 的表现,而且更适合长时间运行的任务。对开发者来说,这个表述比“更聪明”有用得多。
因为现实里的 Agent 工作流,最贵的从来不是一次答错,而是中途跑偏、反复横跳、最后把人类拉回去收拾烂摊子。真正值钱的能力是:
- 长上下文里不丢目标
- 多轮工具调用不失控
- 遇到不确定信息时能稳住,而不是胡编
- 可以在长任务里持续输出一致的工作风格
这也是为什么我现在越来越少只看单点 benchmark。模型在某个测试集上高 3 分,和它在真实任务里少让你救场 3 次,不是一回事。
官方发布页的视觉风格很克制,和这次“强调协作可靠性”的叙事是统一的。
更像一个“工作伙伴”,而不是“回答机器”
Opus 4.8 还有一个很值得注意的变化:Anthropic 同时把 Claude.ai、Claude Code 和性能/速度/成本的组合一起讲,而不是单独讲模型本体。
这说明他们已经默认了一个事实:大模型竞争正在从“谁更会答题”转向“谁更适合工作流”。
具体来说,开发者真正关心的不是模型能不能写一段漂亮代码,而是它能不能在这些场景里稳定工作:
- 读懂仓库结构,再决定从哪里下手。
- 先规划,再执行,不要一上来就乱改。
- 能持续迭代,而不是每一步都像第一次见到项目。
- 在低风险任务里提速,在高风险任务里保守。
这类能力,往往比“某项榜单第一”更接近真实 ROI。
我更在意的其实是这个信号
Opus 4.8 的发布告诉我一件事:前沿模型已经进入“工程化竞争”阶段。过去比的是谁更强,现在比的是谁更稳、谁更可控、谁更适合嵌进生产系统。
这对 Agent 产品尤其重要。因为 Agent 不是聊天框,它会真的去做事。只要它开始做事,稳定性就不再是“体验加分项”,而是“系统边界条件”。
所以如果你现在还在用“模型越新越好”来判断选型,我建议换个问法:
- 它能不能在长任务里保持一致?
- 它对工具调用的理解是否稳定?
- 它在失败时会不会把问题放大?
- 它适不适合你的业务节奏?
回答这些问题,比盯着版本号更有意义。
如果你在多个 AI 模型之间频繁切换,推荐试试 OfoxAI(ofox.ai)——一个账号搞定 Claude、GPT、Gemini 等主流模型,做选型和对比会省很多时间。